Whoever you ask how to build software properly will come up with Make as one of the answers. On GNU/Linux systems, GNU Make [1] is the Open-Source version of the original Make that was released more than 40 years ago — in 1976. Make works with a Makefile — a structured plain text file with that name that can be best described as the construction manual for the software building process. The Makefile contains a number of labels (called targets) and the specific instructions needed to be executed to build each target.
Simply speaking, Make is a build tool. It follows the recipe of tasks from the Makefile. It allows you to repeat the steps in an automated fashion rather than typing them in a terminal (and probably making mistakes while typing).
Listing 1 shows an example Makefile with the two targets “e1” and “e2” as well as the two special targets “all” and “clean.” Running “make e1” executes the instructions for target “e1” and creates the empty file one. Running “make e2” does the same for target “e2” and creates the empty file two. The call of “make all” executes the instructions for target e1 first and e2 next. To remove the previously created files one and two, simply execute the call “make clean.”
Listing 1
e1:
touch one
e2:
touch two
clean:
rm one two
Running Make
The common case is that you write your Makefile and then just run the command “make” or “make all” to build the software and its components. All the targets are built in serial order and without any parallelization. The total build time is the sum of time that is required to build every single target.
This approach works well for small projects but takes rather long for medium and bigger projects. This approach is no longer up-to-date as most of the current cpus are equipped with more than one core and allow the execution of more than one process at a time. With these ideas in mind, we look at whether and how the build process can be parallelized. The aim is to simply reduce the build time.
Make Improvements
There are a few options we have — 1) simplify the code, 2) distribute the single tasks onto different computing nodes, build the code there, and collect the result from there, 3) build the code in parallel on a single machine, and 4) combine options 2 and 3.
Option 1) is not always easy. It requires the will to analyze the runtime of the implemented algorithm and knowledge about the compiler, i.e., how does the compiler translate the instructions in the programming language into processor instructions.
Option 2) requires access to other computing nodes, for example, dedicated computing nodes, unused or less used machines, virtual machines from cloud services like AWS, or rented computing power from services like LoadTeam [5]. In reality, this approach is used to build software packages. Debian GNU/Linux uses the so-called Autobuilder network [17], and RedHat/Fedors uses Koji [18]. Google calls its system BuildRabbit and is perfectly explained in the talk by Aysylu Greenberg [16]. distcc [2] is a so-called distributed C compiler that allows you to compile code on different nodes in parallel and to set up your own build system.
Option 3 uses parallelization at the local level. This may be the option with the best cost-benefit ratio for you, as it does not require additional hardware as in option 2. The requirement to run Make in parallel is adding the option -j in the call (short for –jobs). This specifies the number of jobs that are run at the same time. The listing below asks to Make to run 4 jobs in parallel:
Listing 2
According to Amdahl’s law [23], this will reduce the build time by nearly 50%. Keep in mind that this approach works well if the single targets do not depend on each other; for example, the output of target 5 is not required to build target 3.
However, there is one side effect: the output of the status messages for each Make target appears arbitrary, and these can no longer be clearly assigned to a target. The output order depends on the actual order of the job execution.
Define Make Execution Order
Are there statements that help Make to understand which targets depend on each other? Yes! The example Makefile in Listing 3 says this:
* to build target “all,” run the instructions for e1, e2, and e3
* target e2 requires target e3 to be built before
This means that the targets e1 and e3 can be built in parallel, first, then e2 follows as soon as the building of e3 is completed, finally.
Listing 3
e1:
touch one
e2: e3
touch two
e3:
touch three
clean:
rm one two three
Visualize the Make Dependencies
The clever tool make2graph from makefile2graph [19] project visualizes the Make dependencies as a directed acyclic graph. This helps to understand how the different targets depend on each other. Make2graph outputs graph descriptions in dot format that you can transform into a PNG image using the dot command from the Graphviz project [22]. The call is as follows:
Listing 4
Firstly, Make is called with the target “all” followed by the options “-B” to unconditionally build all the targets, “-n” (short for “–dry-run”) to pretend running the instructions per target, and “-d” (“–debug”) to display debug information. The output is piped to make2graph that pipes its output to dot that generates the image file graph.png in PNG format.
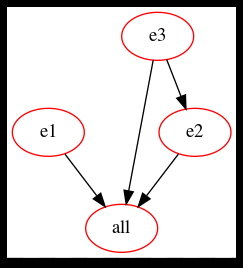
The build dependency graph for listing 3
More Compilers and Build Systems
As already explained above, Make was developed more than four decades ago. Over the years, executing jobs in parallel has become more and more important, and the number of specially designed compilers and build systems to achieve a higher level of parallelization has grown since then. The list of tools includes these:
- Bazel [20]
- CMake [4]: abbreviates cross-platform Make and creates description files later used by Make
- distmake [12]
- Distributed Make System (DMS) [10] (seems to be dead)
- dmake [13]
- LSF Make [15]
- Apache Maven
- Meson
- Ninja Build
- NMake [6]: Make for Microsoft Visual Studio
- PyDoit [8]
- Qmake [11]
- redo [14]
- SCons [7]
- Waf [9]
Most of them have been designed with parallelization in mind and offer a better result regarding build time than Make.
Conclusion
As you have seen, it is worth thinking about parallel builds as it significantly reduces build time up to a certain level. Still, it is not easy to achieve and comes with certain pitfalls [3]. It is recommended to analyse both your code and its build path before stepping into parallel builds.
Links and References
- [1] GNU Make Manual: Parallel Execution, https://www.gnu.org/software/make/manual/html_node/Parallel.html
- [2] distcc: https://github.com/distcc/distcc
- [3] John Graham-Cumming: The Pitfalls and Benefits of GNU Make Parallelization, https://www.cmcrossroads.com/article/pitfalls-and-benefits-gnu-make-parallelization
- [4] CMake, https://cmake.org/
- [5] LoadTeam, https://www.loadteam.com/
- [6] NMake, https://docs.microsoft.com/en-us/cpp/build/reference/nmake-reference?view=msvc-160
- [7] SCons, https://www.scons.org/
- [8] PyDoit, https://pydoit.org/
- [9] Waf, https://gitlab.com/ita1024/waf/
- [10] Distributed Make System (DMS), http://www.nongnu.org/dms/index.html
- [11] Qmake, https://doc.qt.io/qt-5/qmake-manual.html
- [12] distmake, https://sourceforge.net/projects/distmake/
- [13] dmake, https://docs.oracle.com/cd/E19422-01/819-3697/dmake.html
- [14] redo, https://redo.readthedocs.io/en/latest/
- [15] LSF Make, http://sunray2.mit.edu/kits/platform-lsf/7.0.6/1/guides/kit_lsf_guide_source/print/lsf_make.pdf
- [16] Aysylu Greenberg: Building a Distributed Build System at Google Scale, GoTo Conference 2016, https://gotocon.com/dl/goto-chicago-2016/slides/AysyluGreenberg_BuildingADistributedBuildSystemAtGoogleScale.pdf
- [17] Debian Build System, Autobuilder network, https://www.debian.org/devel/buildd/index.en.html
- [18] koji – RPM building and tracking system, https://pagure.io/koji/
- [19] makefile2graph, https://github.com/lindenb/makefile2graph
- [20] Bazel, https://bazel.build/
- [21] Makefile tutorial, https://makefiletutorial.com/
- [22] Graphviz, http://www.graphviz.org
- [23] Amdahl’s law, Wikipedia, https://en.wikipedia.org/wiki/Amdahl%27s_law