The utilities Linux offer often follow the UNIX philosophy of design. Any tool should be small, use plain text for I/O, and operate in a modular manner. Thanks to the legacy, we have some of the finest text processing functionalities with the help of tools like sed and awk.
In Linux, the awk tool comes pre-installed on all Linux distros. AWK itself is a programming language. The AWK tool is just an interpreter of the AWK programming language. In this guide, check out how to use AWK on Linux.
AWK usage
The AWK tool is most useful when texts are organized in a predictable format. It’s quite good at parsing and manipulating tabular data. It operates on a line-by-line basis, on the entire text file.
The default behavior of awk is to use whitespaces (spaces, tabs, etc.) for separating fields. Thankfully, many of the configuration files on Linux follow this pattern.
Basic syntax
This is how the command structure of awk looks like.
The portions of the command are quite self-explanatory. Awk can operate without the search or action portion. If nothing is specified, then the default action on the match will be just printing. Basically, awk will print all the matches found on the file.
If there’s no search pattern specified, then awk will perform the specified actions on every single line of the file.
If both portions are given, then awk will use the pattern to determine whether the current line reflects it. If matched, then awk performs the action specified.
Note that awk can also work on redirected texts. This can be achieved by piping the contents of the command to awk to act on. Learn more about the Linux pipe command.
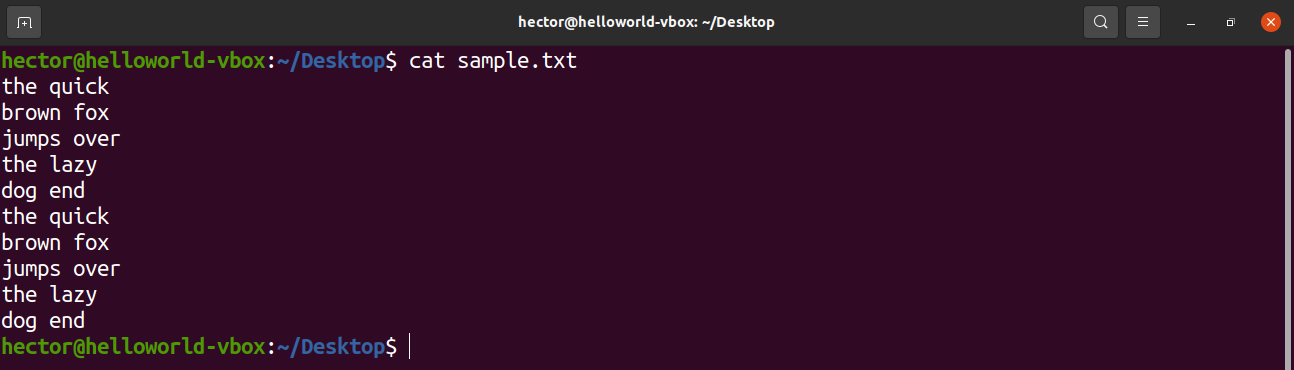
For demo purposes, here’s a sample text file. It contains 10 lines, 2 words per line.
Regular expression
One of the key features that make awk a powerful tool is the support of regular expression (regex, for short). A regular expression is a string that represents a certain pattern of characters.
Here’s a list of some of the most common regular expression syntaxes. These regex syntaxes aren’t just unique to awk. These are almost universal regex syntaxes, so mastering them will also help in other apps/programming that involves regular expression.
- Basic characters: All the alphanumeric characters underscore (_) etc.
- Character set: To make things easier, there are character groups in the regex. For example, uppercase (A-Z), lowercase (a-z), and numeric digits (0-9).
- Meta-characters: These are characters that explain various ways to expand the ordinary characters.
- Period (.): Any character match in the position is valid (except a newline).
- Asterisk (*): Zero or more existences of the immediate character preceding it is valid.
- Bracket ([]): The match is valid if, at the position, any of the characters from the bracket is matched. It can be combined with character sets.
- Caret (^): The match will have to be at the start of the line.
- Dollar ($): The match will have to be at the end of the line.
- Backslash (\): If any meta-character has to be used in the literal sense.
Printing the text
To print all the contents of a text file, use the print command. In the case of the search pattern, there’s no pattern defined. So, awk prints all the lines.
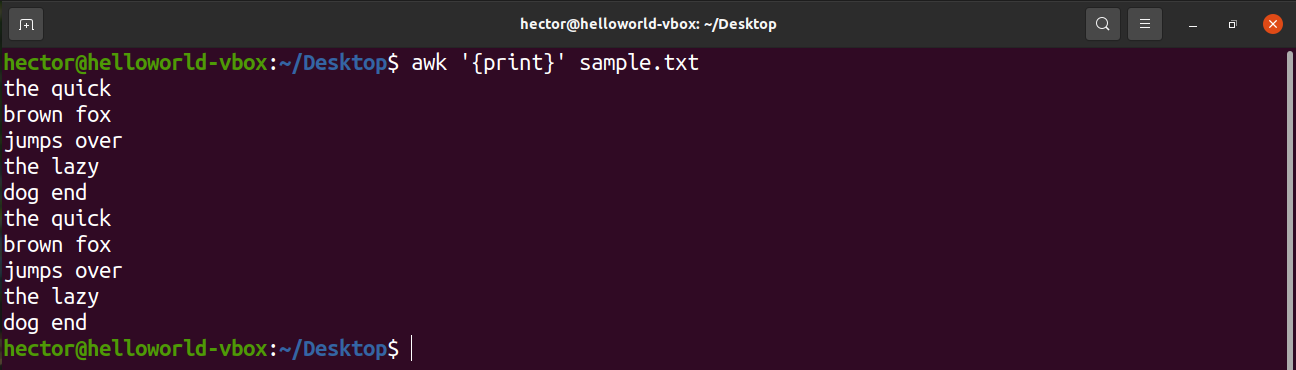
Here, “print” is an AWK command that prints the content of the input.
String search
AWK can perform a basic text search on the given text. In the pattern section, it has to be the text to find.
In the following command, awk will search for the text “quick” on all the lines of the file sample.txt.

Now, let’s use some regular expressions to further fine-tune the search. The following command will print all the lines that have “brown” at the beginning.

How about finding something at the end of a line? The following command will print all the lines that have “quick” at the end.

Wild card pattern
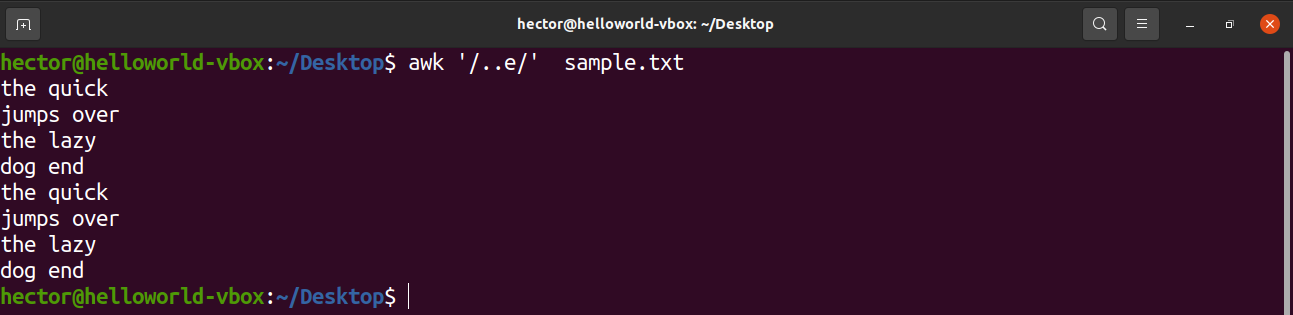
The next example is going to showcase the usage of the caret (.). Here, there can be any two characters before the character “e”.
Wild card pattern (using asterisk)
What if there can be any number of characters at the location? To match for any possible character at the position, use the asterisk (*). Here, AWK will match all the lines that have any amount of characters after “the”.

Bracket expression
The following example is going to showcase how to use the bracket expression. Bracket expression tells that at the location, the match will be valid if it matches the set of characters enclosed by the brackets. For example, the following command will match “The” and “Tee” as valid matches.

There are some predefined character sets in the regular expression. For example, the set of all uppercase letters is labeled as “A-Z”. In the following command, awk will match all the words that contain an uppercase letter.
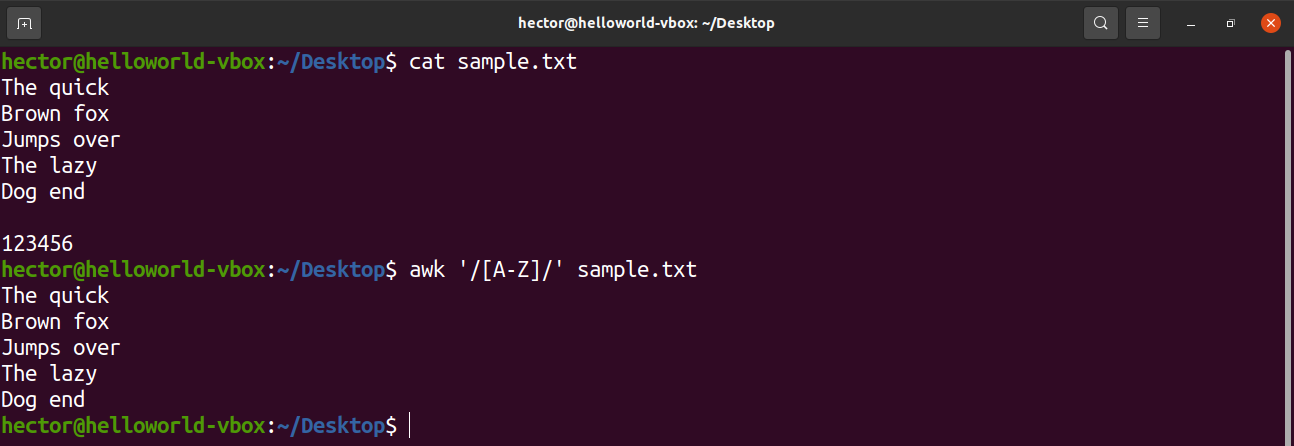
Have a look at the following usage of character sets with bracket expression.
- [0-9]: Indicates a single digit
- [a-z]: Indicates a single lowercase letter
- [A-Z]: Indicates a single uppercase letter
- [a-zA-z]: Indicates a single letter
- [a-zA-z 0-9]: Indicates a single character or digit.
Awk pre-defined variables
AWK comes with a bunch of pre-defined and automatic variables. These variables can make writing programs and scripts with AWK easier.
Here are some of the most common AWK variables that you’ll come across.
- FILENAME: The filename of the current input file.
- RS: The record separator. Because of the nature of AWK, it processes data one record at a time. Here, this variable specifies the delimiter used for splitting the data stream into records. By default, this value is the newline character.
- NR: The current input record number. If the RS value is set to default, then this value will indicate the current input line number.
- FS/OFS: The character(s) used as the field separator. Once read, AWK splits a record into different fields. The delimiter is defined by the value of FS. When printing, AWK rejoins all the fields. However, at this time, AWK uses the OFS separator instead of the FS separator. Generally, both FS and OFS are the same but not mandatory to be so.
- NF: The number of fields in the current record. If the default value “whitespace” is used, then it’ll match the number of words in the current record.
- ORS: The record separator for the output data. The default value is the newline character.
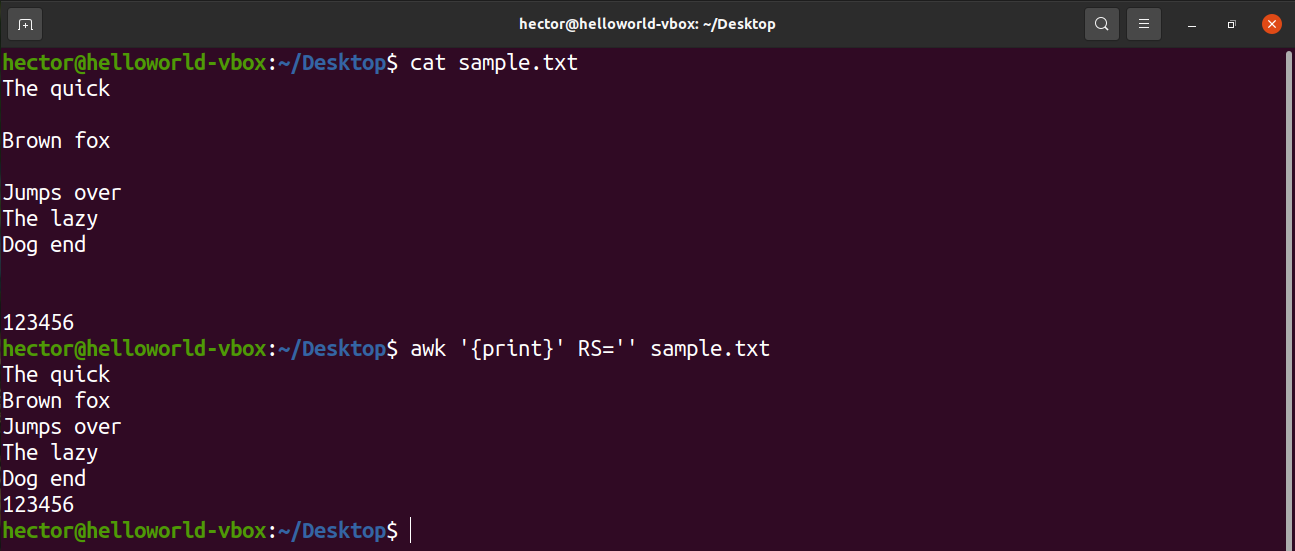
Let’s check them in action. The following command will use the NR variable to print line 2 to line 4 from sample.txt. AWK also supports logical operators like logical and (&&).

To assign a specific value to an AWK variable, use the following structure.
For example, to remove all the blank lines from the input file, change the value of RS to basically nothing. It’s a trick that uses an obscure POSIX rule. It specifies that if the value of RS is an empty string, then records are separated by a sequence that consists of a newline with one or more blank lines. In POSIX, a blank line with no content is completely empty. However, if the line contains whitespaces, then it’s not considered “blank”.
Additional resources
AWK is a powerful tool with tons of features. While this guide covers a lot of them, it’s still just the basics. Mastering AWK will take more than just this. This guide should be a nice introduction to the tool.
If you really want to master the tool, then here are some additional resources you should check out.
- Trim whitespace
- Using a conditional statement
- Print a range of columns
- Regex with AWK
- 20 AWK examples
Internet is quite a good place to learn something. There are plenty of awesome tutorials on AWK basics for very advanced users.
Final thought
Hopefully, this guide helped provide a good understanding of the AWK basics. While it may take a while, mastering AWK is extremely rewarding in terms of the power it bestows.
Happy computing!
]]>Example 1: Print a range of columns from a command output
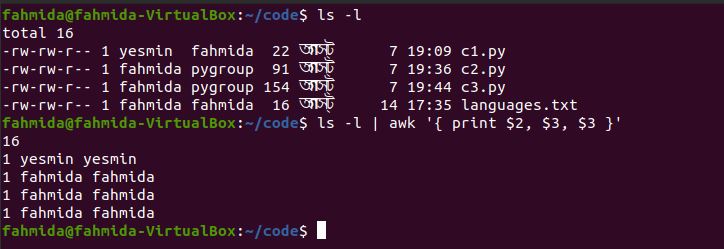
The following command will print the second, third, and fourth columns from the command output, ‘ls -l‘. Here, the column numbers are stated explicitly, but a more efficient command for printing the same range of columns is shown in the next example.
The following output is produced by the command above.
Example 2: Print the range of columns from a file by using a for loop
To follow along with this example and the other examples in this tutorial, create a text file named marks.txt with the following content:
1109 78 87 79
1167 67 81 70
1190 56 61 69
1156 89 55 78
199 54 66 58
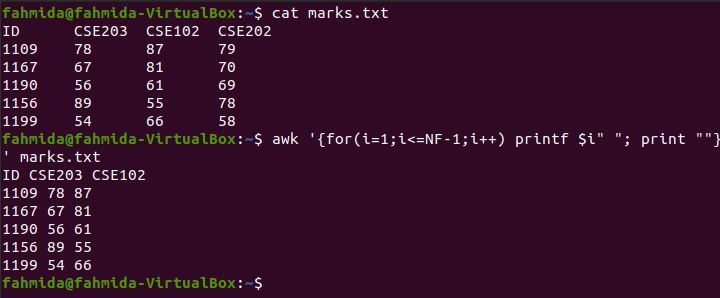
The following `awk` command will print the first three columns of marks.txt. The for loop is used to print the column values, and the loop includes three steps. The NF variable indicates the total numbers of fields or columns of the file.
$ awk '{for(i=1;i<=NF-1;i++) printf $i" "; print ""}' marks.txt
The following output will be produced by running the command. The output shows the student IDs and the marks for CSE203 and CSE102.
Example 3: Print the range of columns by defining starting and ending variables
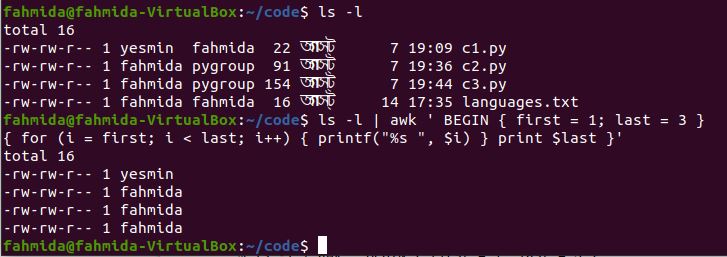
The following `awk` command will print the first three columns from the command output ‘ls -l’ by initializing the starting and ending variables. Here, the value of the starting variable is 1, and the value of the ending variable is 3. These variables are iterated over in a for loop to print the column values.
{ for (i = first; i < last; i++) { printf("%s ", $i) } print $last }'
The following output will appear after running the command. The output shows the first three column values of the output, ‘ls -l’.
Example 4: Print a range of columns from a file with formatting
The following `awk` command will print the first three columns of marks.txt using printf and output field separator (OFS). Here, the for loop includes three steps, and three columns will be printed in sequence from the file. OFS is used here to add space between columns. When the counter value of the loop (i) equals the ending variable, then a newline(\n) is generated.
$ awk -v start=1 -v end=3 '{ for (i=start; i<=end;i++) printf("%s%s",
$i,(i==end) ? "\n" : OFS) }' marks.txt
The following output will be generated after running the above commands.
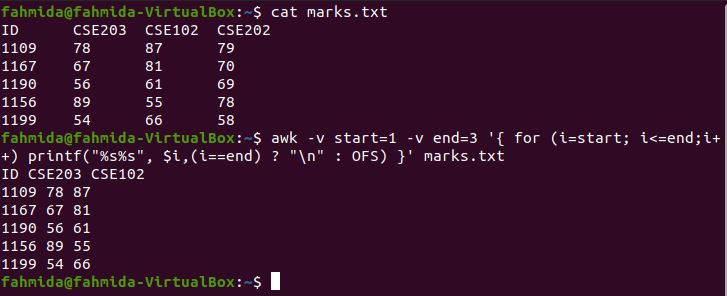
Example 5: Print the range of columns from a file using a conditional statement
The following `awk` command will print the first and last columns from a file by using a for loop and an if statement. Here, the for loop includes four steps. The starting and ending variables are used in the script to omit the second and third columns from the file by using the if condition. The OFS variable is used to add space between the columns, and the ORS variable is used to add a newline(\n) after printing the last column.
$ awk -v start=2 -v end=3 '{ for (i=1; i<=NF;i++)
if( i>=start && i<=end) continue;
else printf("%s%s", $i,(i!=NF) ? OFS : ORS) }' marks.txt
The following output will appear after running the above commands. The output shows the first and last columns of marks.txt.
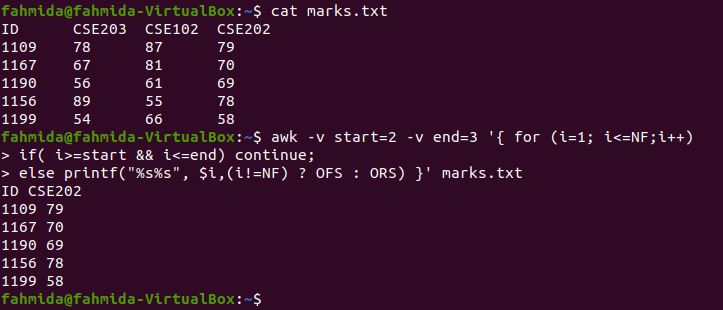
Example 6: Print the range of columns from a file using the NF variable
The following `awk` command will print the first and last columns from the file by using an NF variable. No loops or conditional statements are used to print the column values. NF indicates the number of fields. There are four columns in marks.txt. $(NF-3) defines the first column, and $NF indicates the last column.
$ awk '{print $(NF-3)" "$NF}' marks.txt
The following output is produced by running the above commands. The output shows the first and last columns of marks.txt.
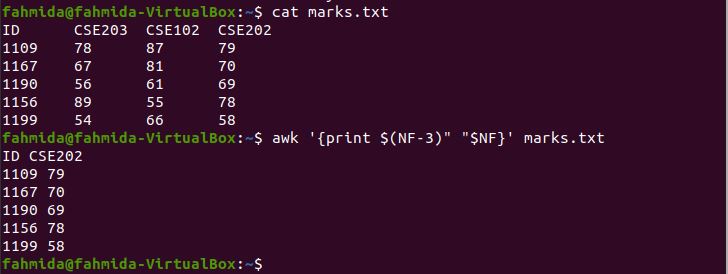
Example 7: Print the range of columns from a file using substr() and index()
The index() function returns a position if the second argument value exists in the first argument value. The substr() function can take three arguments. The first argument is a string value, the second argument is the starting position, and the third argument is the length. The third argument of substr() is omitted in the following command. Because the column starts from $1 in the `awk` command, the index() function will return $3, and the command will print from $3 to $4.
$ awk '{print substr($0,index($0,$3))}' marks.txt
The following output will be produced by running the above commands.
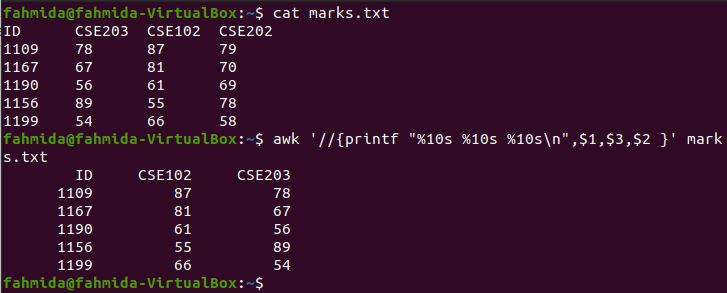
Example 8: Sequentially print a range of columns from a file using printf
The following `awk` command will print the first, second, and third columns of marks.txt by setting enough space for 10 characters.
$ awk '//{printf "%10s %10s %10s\n",$1,$3,$2 }' marks.txt
The following output will be produced by running the above commands.
Conclusion
There are various ways to print the range of columns from the command output or a file. This tutorial shows how `awk` command can help Linux users to print content from tabular data.
]]>Linux’s `awk` command is a powerful utility for different operations on text files such as search, replace, and print. It is easy to use with tabular data because it automatically divides each line into fields or columns based on the field separator. When you work with a text file that contains tabular data and want to print the data of a particular column, then the `awk` command is the best option. In this tutorial, we will show you how to print the first column and/or last column of a line or text file.
Print the first column and/or last column of a command output
Many Linux commands such as the ‘ls’ command generate tabular outputs. Here, we will show you how to print the first column and/or last column from the output of the ‘ls -l’ command.
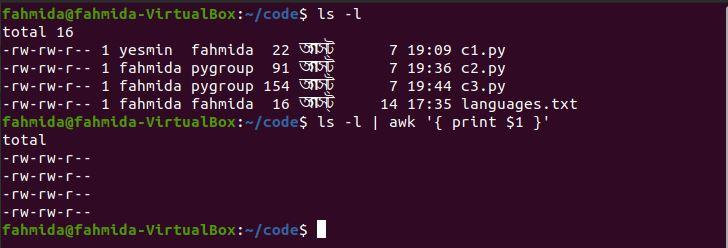
Example 1: Print the first column of a command output
The following `awk` command will print the first column from the output of the ‘ls -l’ command.
$ ls -l | awk '{ print $1 }'
The following output will be produced after running the above commands.
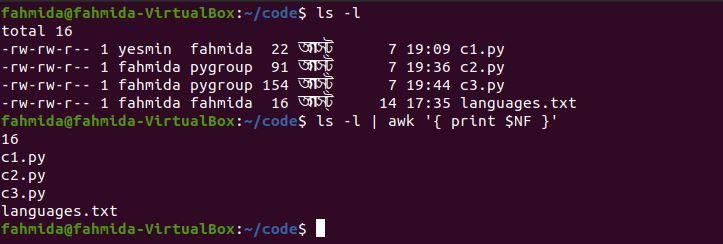
Example 2: Print the last column of a command output
The following `awk` command will print the last column from the output of the ‘ls -l’ command.
$ ls -l | awk '{ print $NF }'
The following output will be produced after running the above commands.
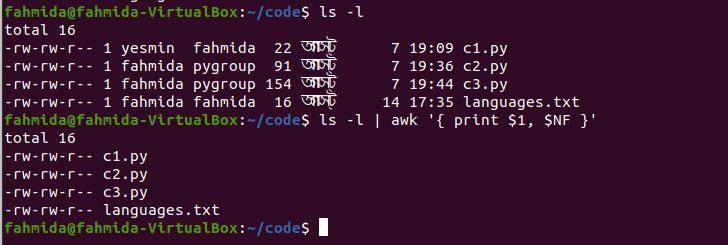
Example 3: Print the first and last columns of a command output
The following `awk` command will print the first and last columns from the output of the ‘ls -l’ command.
$ ls -l | awk '{ print $1, $NF }'
The following output will be produced after running the above commands.
Print the first column and/or last column of a text file
Here, we will show you how to use the `awk` command to print the first column and/or last column of a text file.
Create a text file
To follow along with this tutorial, create a text file named customers.txt with the following content. The file contains three types of customer data: name with id, email, and phone number. The tab character (\t) is used to separate these values.
Jonathon Bing - 1001 [email protected] 01967456323
Micheal Jackson - 2006 [email protected] 01756235643
Janifer Lopez - 3029 [email protected] 01822347865
John Abraham - 4235 [email protected] 01590078452
Mir Sabbir - 2756 [email protected] 01189523978
Example 4: Print the first column of a file without using a field separator
If no field separator is used in the `awk` command, then a space is used as the default field separator. The following `awk` command will print the first column by using the default separator.
$ awk '{print $1}' customers.txt
The following output will be produced after running the above commands. Note that the output shows only the customer’s first name because the space is applied as the field separator. The solution to this problem is shown in the next example.
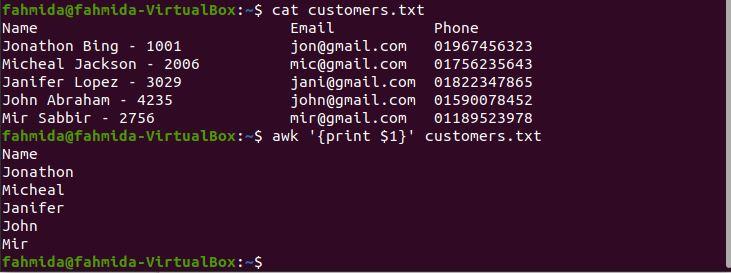
Example 5: Print the first column of a file with a delimiter
Here, \t is used as a field separator to print the first column of the file. The ‘-F’ option is used to set the field separator.
$ awk -F '\t' '{print $1}' customers.txt
The following output will be produced after running the above commands. The content of the file is divided into three columns based on \t. Therefore, the customer’s name and id are printed as the first column. If you want to print the customer’s name without the id, then continue to the next example.
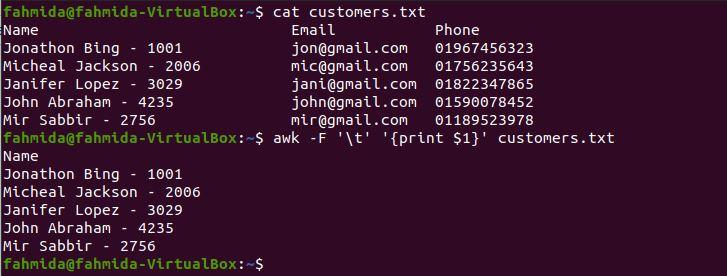
If you want to print the customer’s name without the id, then you have to use ‘-‘ as a field separator. The following `awk` command will print the customer’s name only as the first column.
$ awk -F '-' '{print $1}' customers.txt
The following output will be produced after running the above commands. The output includes the full names of the customers without their ids.
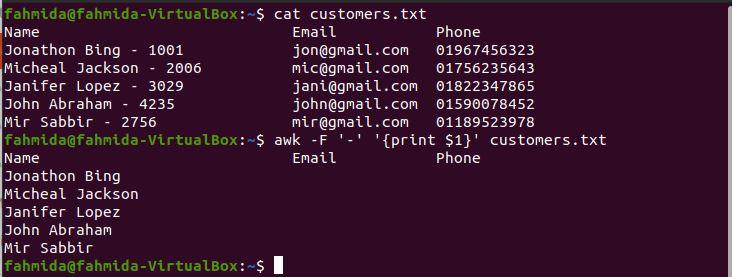
Example 6: Print the last column of a file
The following `awk` command will print the last column of customers.txt. Because no field separator is used in the command, the space will be used as a field separator.
$ awk '{print $NF}' customers.txt
The following output will be produced after running the above commands. The last column contains phone numbers, as shown in the output.
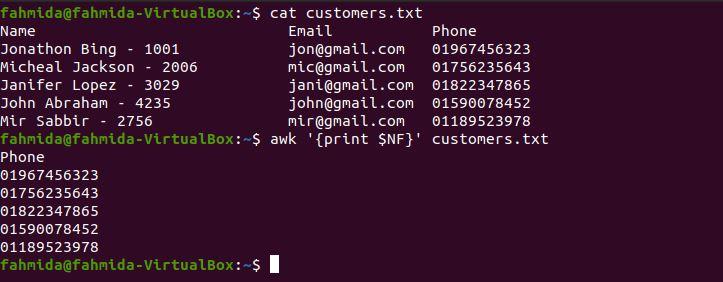
Example 7: Print the first and last columns of a file
The following `awk` command will print the first and last columns of customers.txt. Here, tab (\t) is used as the field separator to divide the content into columns. Here, tab (\t) is used as a separator for the output.
$ awk -F "\t" '{print $1 "\t" $NF}' customers.txt
The following output will appear after running the above commands. The content is divided into three columns by \t; the first column contains the customer’s name and id and the second column contains the phone number. The first and last columns are printed by using \t as a separator.
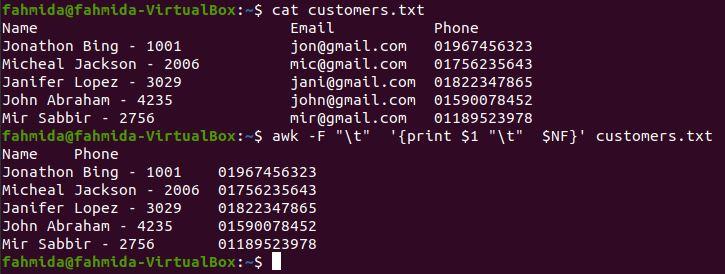
Conclusion
The `awk` command can be applied in different ways to get the first column and/or last column from any command output or from tabular data. It is important to note that a field separator is required in the command, and if one is not provided, then the space is used.
]]>There are various uses of the `awk` command in Linux. For example, it can be used to print the content of a text file. The first line of many text files contains the heading of the file, and sometimes, the first line must be skipped when printing the content of the file. In this tutorial, we will show you how to accomplish this task by using the `awk` command.
Create a text file
To follow along with this tutorial, create a tab-delimited text file named booklist.txt with the following content. This file contains a list of books with their corresponding authors. In this tutorial, we will show you how to print different parts of this file after skipping the first line.
Command Line Kung Fu Jason Cannon
Linux Command Line Travis Booth
Bash in easy steps Mike McGrath
Unix in easy steps Mike McGrath
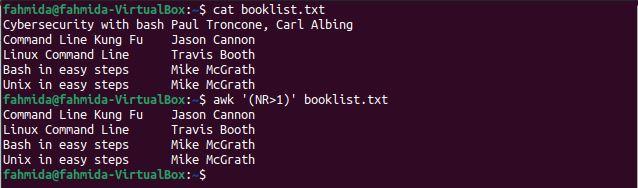
Example 1: Skip the first line of a file using NR and the ‘>’ operator
The NR variable indicates the number of records in a file. The following `awk` command uses the NR variable to skip the first line of a file. The value of NR is 1 for the first line. The following command will print lines for which the NR value is greater than 1.
$ awk '(NR>1)' booklist.txt
The following output will be produced after running the above commands. The output includes all lines other than the first line of the file.
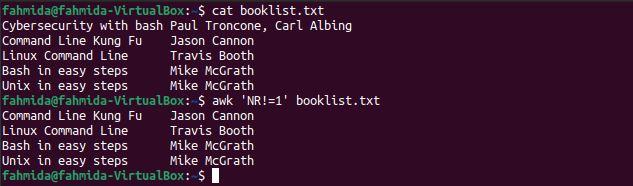
Example 2: Skip the first line by using NR and the ‘!=’ operator
The following `awk` command is similar to that in the previous example. However, the ‘!=’ comparison operator is used here instead of ‘>’.
$ awk 'NR!=1' booklist.txt
The following output will be produced after running the above commands. The output shows all lines other than the first line of the file.
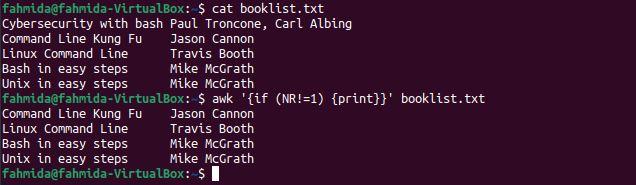
Example 3: Skip the first line of a file by using a conditional statement
The following `awk` command will print the lines of the file if the if statement is true. Here, the if statement will be true only when the NR value does not equal 1.
$ awk '{if (NR!=1) {print}}' booklist.txt
The following output will be produced after running the above commands. The output includes all lines except the first line of the file.
Example 4: Print the book names from the file but skip the first line
Two `awk` commands are used in this example to print all book names except the first. The `awk` command will read the first column from the file based on the field separator (\t) and send the output to the second `awk` command. The second `awk` command will print the desired output.
$ awk -F "\t" '{print $1}' booklist.txt | awk 'NR!=1 {print}'
The following output will be produced after running the above commands. The output shows all the book names except for that of the first book.
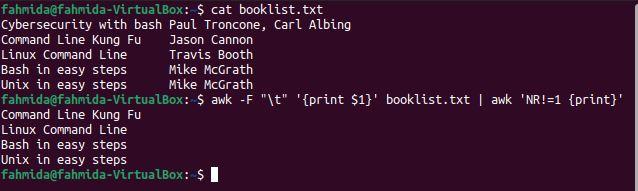
Example 5: Format the file content after skipping the first line
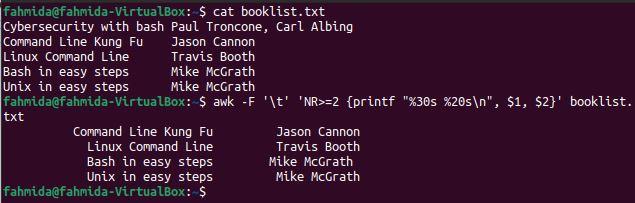
The ‘-F’ option, NR variable, and printf function are used in the following `awk` command to generate formatted output after skipping the first line. The command will divide the file content into columns based on \t, and printf will print the first and second columns when the NR value is at least 2.
$ awk -F '\t' 'NR>=2 {printf "%30s %20s\n", $1, $2}' booklist.txt
The following output will be produced after running the above commands. The output shows the formatted content of the file, excluding the first line of the file.
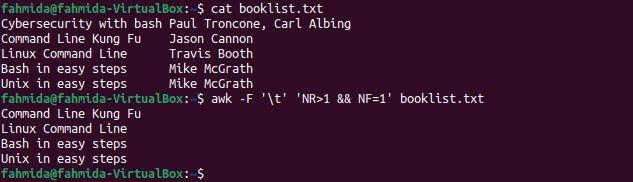
Example 6: Print the book names after skipping the first line using NR and NF
The following `awk` command uses the ‘-F’ option and NR and NF to print the book names after skipping the first book. The ‘-F’ option is used to separate the content of the file base on \t. NR is used to skip the first line, and NF is used to print the first column only.
$ awk -F '\t' 'NR>1 && NF=1' booklist.txt
The following output will be produced after running the above commands. The output includes all the book names in the file except for that of the first book.
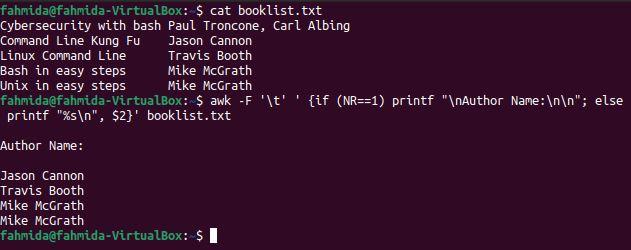
Example 7: Print the formatted author names after skipping the first line
The following `awk` command uses the ‘-F’ option and a conditional statement to print the author names after skipping the first line. Here, the NR value is used in the if condition. Here, “Author Name:\n\n” will be printed as the first line instead of the content from the first line. The author’s names from the file will be printed for the other values of NR.
$ awk -F '\t' ' {if (NR==1) printf "\nAuthor Name:\n\n"; else printf "%s\n", $2}' booklist.txt
The following output will be produced after running the above commands. The output shows the text, “Author Name:” with a newline, and all author names are printed except the first one.
Conclusion
The first line of a file can be skipped by using various Linux commands. As shown in this tutorial, there are different ways to skip the first line of a file by using the `awk` command. Noteably, the NR variable of the `awk` command can be used to skip the first line of any file.
]]>A regular expression (regex) is used to find a given sequence of characters within a file. Symbols such as letters, digits, and special characters can be used to define the pattern. Various tasks can be easily completed by using regex patterns. In this tutorial, we will show you how to use regex patterns with the `awk` command.
The basic characters used in patterns
Many characters can be used to define a regex pattern. The characters most commonly used to define regex patterns are defined below.
| Character | Description |
|---|---|
| . | Match any character without a newline (\n) |
| \ | Quote a new meta-character |
| ^ | Match the beginning of a line |
| $ | Match the end of a line |
| | | Define an alternate |
| () | Define a group |
| [] | Define a character class |
| \w | Match any word |
| \s | Match any white space character |
| \d | Match any digit |
| \b | Match any word boundary |
Create a file
To follow along with this tutorial, create a text file named products.txt. The file should contain four fields: ID, Name, Type, and Price.
ID Name Type Price
p1001 15″Monitor Monitor $100
p1002 A4tech Mouse Mouse $10
p1003 Samsung Printer Printer $50
p1004 HP Scanner Scanner $60
p1005 Logitech Mouse Mouse $15
Example 1: Define a regex pattern using the character class
The following `awk` command will search for and print lines containing the character ‘n’ followed by the characters ‘er’.
$ awk '/[n][er]/ {print $0}' products.txt
The following output will be produced after running the above commands. The output shows the line that matches the pattern. Here, only one line matches the pattern.
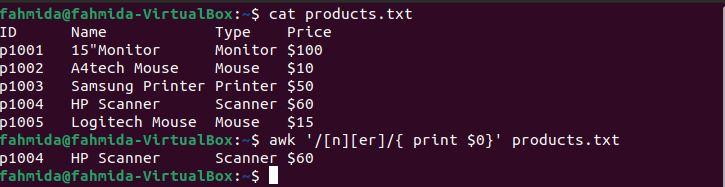
Example 2: Define a regex pattern using the ‘^’ symbol
The following `awk` command will search for and print lines that start with the character ‘p’ and include the number 3.
$ awk '/^p.*3/ {print $0}' products.txt
The following output will be produced after running the above commands. Here, there is one line that matches the pattern.
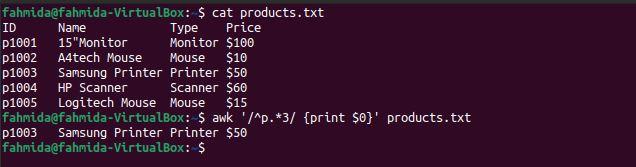
Example 3: Define a regex pattern using the gsub function
The gsub() function is used to globally search for and replace text. The following `awk` command will search for the word ‘Scanner’ and replace it with the word ‘Router’ before printing the result.
$ awk 'gsub(/Scanner/, "Router")' products.txt
The following output will be produced after running the above commands. There is one line that contains the word ‘Scanner‘, and ‘Scanner‘ is replaced by the word ‘Router‘ before the line is printed.
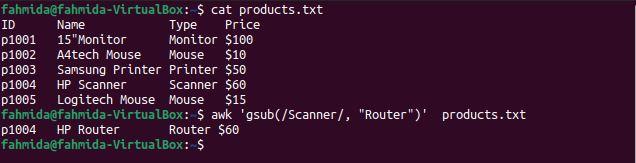
Example 4: Define a regex pattern with ‘*’
The following `awk` command will search for and print any string that starts with ‘Mo’ and includes any subsequent character.
$ awk '/Mo*/ {print $0}' products.txt
The following output will be produced after running the above commands. Three lines match the pattern: two lines contain the word ‘Mouse‘ and one line contains the word ‘Monitor‘.
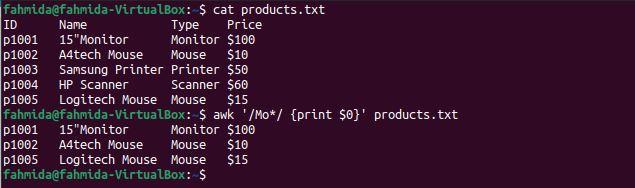
Example 5: Define a regex pattern using the ‘$’ symbol
The following `awk` command will search for and print lines in the file that end with the number 5.
$ awk '/5$/ {print $0}' products.txt
The following output will be produced after running the above commands. There is only one line in the file that ends with the number 5.
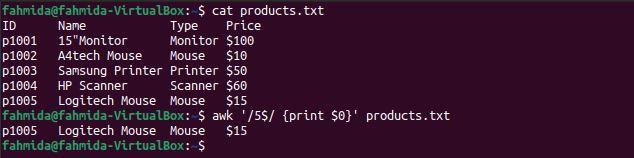
Example 6: Define a regex pattern using the ‘^’ and ‘|’ symbols
The ‘^‘ symbol indicates the start of a line, and the ‘|‘ symbol indicates a logical OR statement. The following `awk` command will search for and print lines that start with the character ‘p‘ and contain either ‘Scanner‘ or ‘Mouse‘.
$ awk '/^p.* (Scanner|Mouse)/' products.txt
The following output will be produced after running the above commands. The output shows that two lines contain the word ‘Mouse‘ and one line contains the word ‘Scanner‘. The three lines start with the character ‘p‘.
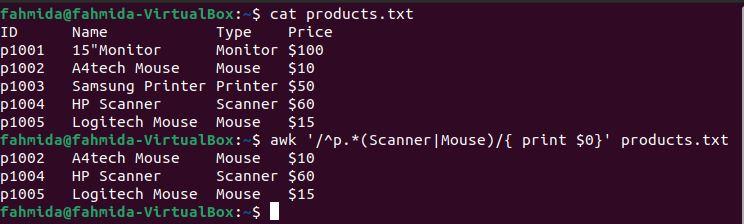
Example 7: Define a regex pattern using the ‘+’ symbol
The ‘+‘ operator is used to find at least one match. The following `awk` command will search for and print lines that contain the character ‘n‘ at least once.
$ awk '/n+/{print}' products.txt
The following output will be produced after running the above commands. Here, the character ‘n‘ contains occurs at least once in the lines that contain the words Monitor, Printer, and Scanner.
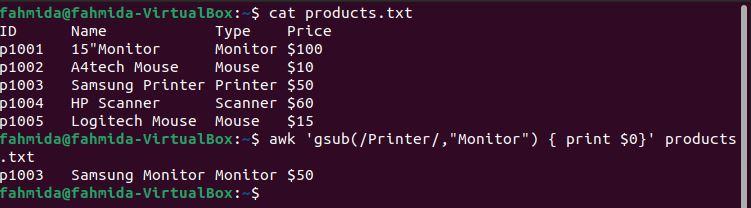
Example 8: Define a regex pattern using the gsub() function
The following `awk` command will globally search for the word ‘Printer‘ and replace it with the word ‘Monitor‘ using the gsub() function.
$ awk 'gsub(/Printer/, “Monitor”) { print$0}' products.txt
The following output will be produced after running the above commands. The fourth line of the file contains the word ‘Printer‘ twice, and in the output, ‘Printer‘ has been replaced by the word ‘Monitor‘.
Conclusion
Many symbols and functions can be used to define regex patterns for different search and replace tasks. Some symbols commonly used in regex patterns are applied in this tutorial with the `awk` command.
]]>`tab` is used as a separator In the tab-delimited file. This type of text file is created to store various types of text data in a structured format. Different types of command exist in Linux to parse this type of file. `awk` command is one of the ways to parse the tab-delimited file in different ways. The uses of the `awk` command to read the tab-delimited file has shown in this tutorial.
Create a tab-delimited file:
Create a text file named users.txt with the following content to test the commands of this tutorial. This file contains the user’s name, email, username, and password.
users.txt
Md. Robin [email protected] robin89 563425
Nila Hasan [email protected] nila78 245667
Mirza Abbas [email protected] mirza23 534788
Aornob Hasan [email protected] arnob45 778473
Nuhas Ahsan [email protected] nuhas34 563452
Example-1: Print the second column of a tab-delimited file using the -F option
The following `sed` command will print the second column of a tab-delimited text file. Here, the ‘-F’ option is used to define the field separator of the file.
$ awk -F '\t' '{print $2}' users.txt
The following output will appear after running the commands. The second column of the file contains the user’s email addresses, which are displaying as output.

Example-2: Print the first column of a tab-delimited file using the FS variable
The following `sed` command will print the first column of a tab-delimited text file. Here, FS ( Field Separator) variable is used to define the field separator of the file.
$ awk '{ print $1 }' FS='\t' users.txt
The following output will appear after running the commands. The first column of the file contains the user’s names, which are displaying as output.

Example-3: Print the third column of a tab-delimited file with formatting
The following `sed` command will print the third column of the tab-delimited text file with formatting by using the FS variable and printf. Here, the FS variable is used to define the field separator of the file.
$ awk 'BEGIN{FS="\t"} {printf "%10s\n", $3}' users.txt
The following output will appear after running the commands. The third column of the file contains the username that has been printed here.

Example-4: Print the third and fourth columns of the tab-delimited file by using OFS
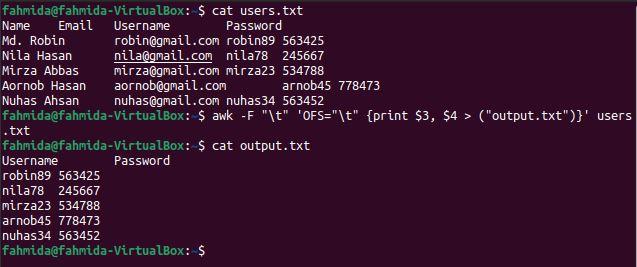
OFS (Output Field Separator) is used to add a field separator in the output. The following `awk` command will divide the content of the file based on tab(\t) separator and print the 3rd and 4th columns using the tab(\t) as a separator.
$ awk -F "\t" 'OFS="\t" {print $3, $4 > ("output.txt")}' users.txt
$ cat output.txt
The following output will appear after running the above commands. The 3rd and 4th columns contain the username and password, which have been printed here.
Example-5: Substitute the particular content of the tab-delimited file
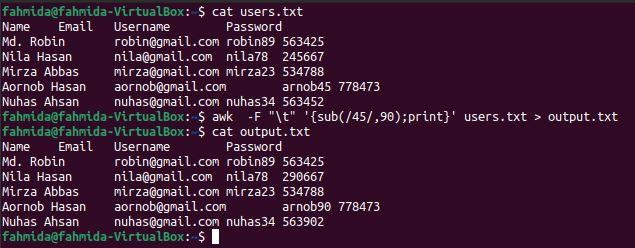
sub() function is used in `awk to command for substitution. The following `awk` command will search the number 45 and substitute with the number 90 if the searching number exists in the file. After the substitution, the content of the file will be stored in the output.txt file.
$ awk -F "\t"'{sub(/45/,90);print}' users.txt > output.txt
$ cat output.txt
The following output will appear after running the above commands. The output.txt file shows the modified content after applying the substitution. Here, the content of the 5th line has modified, and ‘arnob45’ is changed to ‘arnob90’.
Example-6: Add string at the beginning of each line of a tab-delimited file
In the following, the `awk` command, the ‘-F’ option is used to divide the content of the file based on the tab(\t). OFS has used to add a comma(,) as a field separator in the output. sub() function is used to add the string ‘—→’ at the beginning of each line of the output.
$ awk -F "\t" '{{OFS=","};sub(/^/, "---->");print $1,$2,$3}' users.txt
The following output will appear after running the above commands. Each field value is separated by comma(,) and a string is added at the beginning of each line.

Example-7: Substitute the value of a tab-delimited file by using the gsub() function
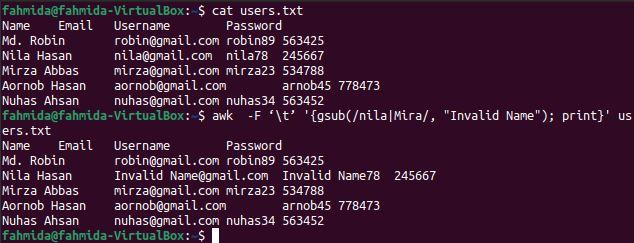
gsub() function is used in the `awk` command for global substitution. All string values of the file will replace where the searching pattern matches. The main difference between the sub() and gsub() functions is that sub() function stops the substitution task after finding the first match, and the gsub() function searches the pattern at the end of the file for substitution. The following `awk` command will search the word ‘nila’ and ‘Mira’ globally in the file and substitute all occurrences by the text, ‘Invalid Name’, where the searching word matches.
$ awk -F ‘\t’ '{gsub(/nila|Mira/, "Invalid Name"); print}' users.txt
The following output will appear after running the above commands. The word ‘nila’ exists two times in the 3rd line of the file that has been replaced by the word ‘Invalid Name’ in the output.
Example-8: Print the formatted content from a tab-delimited file
The following `awk` command will print the first and the second columns of the file with formatting by using printf. The output will show the user’s name by enclosing the email address in brackets.
$ awk -F '\t' '{printf "%s(%s)\n", $1,$2}' users.txt
The following output will appear after running the above commands.

Conclusion
Any tab-delimited file can be easily parsed and printed with another delimiter by using the `awk` command. The ways of parsing tab-delimited files and printing in different formats have shown in this tutorial by using multiple examples. The uses of sub() and gsub() functions in the `awk` command for substituting the content of the tab-delimited file are also explained in this tutorial. I hope this tutorial will help the readers to parse the tab-delimited file easily after practicing the examples of this tutorial properly.
]]>The following include some scenarios in which removing whitespaces might be necessary:
- To reformat source code
- To clean up data
- To simplify command-line outputs
It is possible to remove whitespaces manually if a file that contains only a few lines. But, for a file containing hundreds of lines, then it will be difficult to remove all the whitespaces manually. There are various command-line tools available for this purpose, including sed, awk, cut, and tr. Among these tools, awk is one of the most powerful commands.
What Is Awk?
Awk is a powerful and useful scripting language used in text manipulation and report generation. The awk command is abbreviated using the initials each of the people (Aho, Weinberger, and Kernighan) who developed it. Awk allows you to define variables, numeric functions, strings, and arithmetic operators; create formatted reports; and more.
This article explains the usage of the awk command for trimming whitespaces. After reading this article, you will learn how to use the awk command to perform the following:
- Trim all whitespaces in a file
- Trim leading whitespaces
- Trim trailing whitespaces
- Trim both leading and trailing whitespaces
- Replace multi spaces with a single space
The commands in this article were performed on an Ubuntu 20.04 Focal Fossa system. However, the same commands can also be performed on other Linux distributions. We will use the default Ubuntu Terminal application for running the commands in this article. You can access the terminal using the Ctrl+Alt+T keyboard shortcut.
For demonstration purposes, we will use the sample file named “sample.txt.” to perform the examples provided in this article.
View All Whitespaces in a File
To view all the whitespaces present in a file, pipe the output of the cat command to the tr command, as follows:
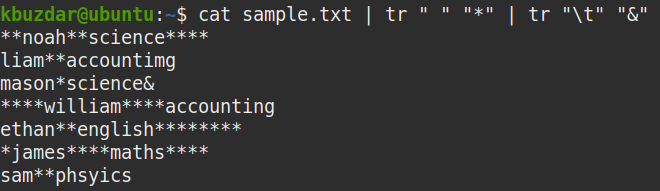
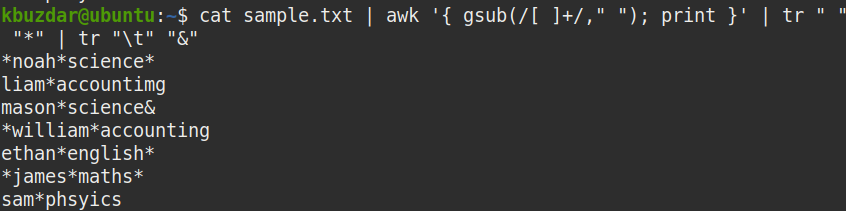
This command will replace all the whitespaces in the given file with the (*) character. After entering this command, you will be able to see clearly where all the whitespaces (including both leading and trailing whitespaces) are present in the file.
The * characters in the following screenshot show where all the whitespaces are present in the sample file. A single * represents single whitespace.
Trim All Whitespaces
To remove all the whitespaces from a file, pipe the out of cat command to the awk command, as follows:
Where
- gsub (stands for global substitution) is a substitution function
- / / represent white space
- “” represents nothing (trim the string)
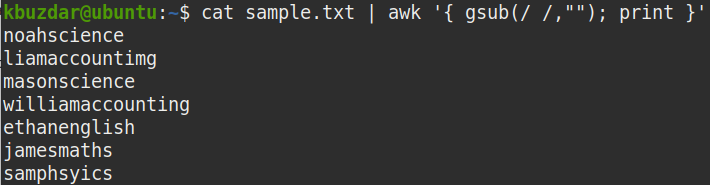
The above command replaces all whitespaces (/ /) with nothing (“”).
In the following screenshot, you can see that all the whitespaces, including the leading and trailing whitespaces, have been removed from the output.
Trim Leading Whitespaces
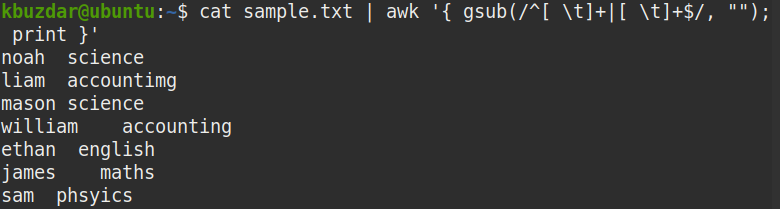
To remove only the leading whitespaces from the file, pipe the out of cat command to the awk command, as follows:
Where
- sub is a substitution function
- ^ represents the beginning of the string
- [ \t]+ represents one or more spaces
- “” represents nothing (trim the string)
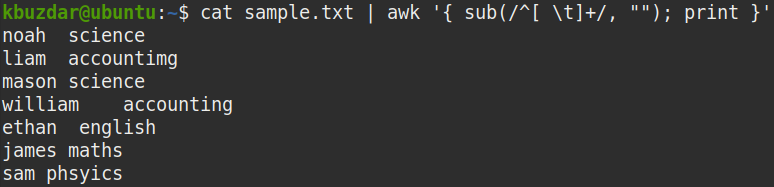
The above command replaces one or more spaces at the beginning of the string (^[ \t]+ ) with nothing (“”) to remove the leading whitespaces.
In the following screenshot, you can see that all the leading whitespaces have been removed from the output.
You can use the following command to verify that the above command has removed the leading whitespaces:
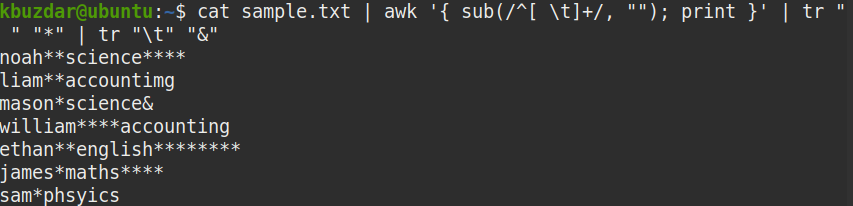
tr "\t" "&"
In the screenshot below, it is clearly visible that only the leading whitespaces have been removed.
Trim Trailing Whitespaces
To remove only the trailing whitespaces from a file, pipe the out of cat command to the awk command, as follows:
Where
- sub is a substitution function
- [ \t]+ represents one or more spaces
- $ represents the end of the string
- “” represents nothing (trim the string)
The above command replaces one or more spaces at the end of the string ([ \t]+ $) with nothing ( “”) to remove the trailing whitespaces.
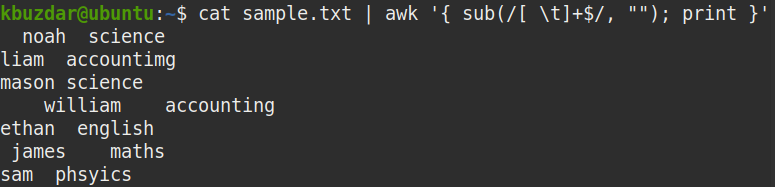
You can use the following command to verify that the above command has removed the trailing whitespaces:
From the below screenshot, it is clearly visible that the trailing whitespaces have been removed.
Trim Both Leading and Trailing Whitespaces
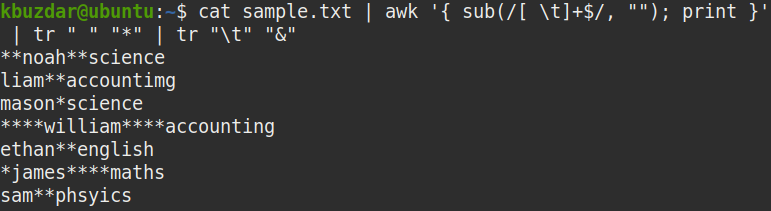
To remove both the leading and trailing whitespaces from a file, pipe the out of cat command to the awk command, as follows:
Where
- gsub is a global substitution function
- ^[ \t]+ represents leading whitespaces
- [ \t]+$ represents trailing whitespaces
- “” represents nothing (trim the string)
The above command replaces both the leading and trailing spaces (^[ \t]+ [ \t]+$) with nothing (“”) to remove them.
To determine whether the above command has removed both the leading and trailing whitespaces in the file, use the following command:
tr " " "*" | tr "\t" "&"
From the below screenshot, it is clearly visible that both the leading and trailing whitespaces have been removed, and only the whitespaces between the strings remain.

Replace Multiple Spaces with Single Space
To replace multiple spaces with a single space, pipe the out of cat command to the awk command, as follows:
Where:
- gsub is a global substitution function
- [ ]+ represents one or more whitespaces
- “ ” represents one white space
The above command replaces multiple whitespaces ([ ]+) with a single white space (“ “).
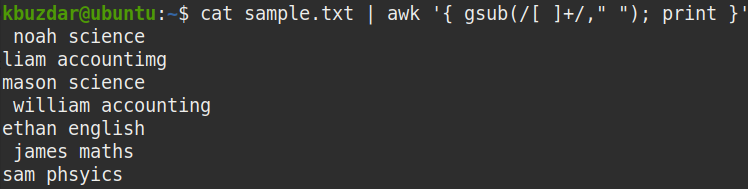
You can use the following command to verify that the above command has replaced the multiple spaces with the whitespaces:
There were multiple spaces in our sample file. As you can see, multiple whitespaces in the sample.txt file were replaced with a single white space by using the awk command.
To trim the whitespaces in only those lines that contain a specific character, such as a comma, colon, or semi-colon, use the awk command with the -F input separator.
For instance, shown below is our sample file that contains whitespaces in each line.
To remove the whitespaces from only the lines that contain a comma (,), the command would be as follows:
Where (-F,) is the input field separator.
The above command will only remove and display the whitespaces from the lines that contain the specified character (,) in them. The rest of the lines will remain unaffected.

Conclusion
That is all you need to know to trim the whitespaces in your data using the awk command. Removing the whitespaces from your data may be required for several different reasons. Whatever the reason is, you can easily trim all the whitespaces in your data using the commands described in this article. You can even trim leading or trailing whitespaces, trim both leading and trailing whitespaces, and replace multi spaces with a single space with the awk command.
]]>However, there are situations in which you do not intend to read the entire content of that file rather you are only concerned with a specific portion of that file. In such a situation, it is highly not recommended to read the entire file since it will occupy extra space and will also take a longer time for processing rather you should directly hit that particular portion of that file. In this article, we aim to walk you through the different methods of using the “awk” command to print the last column from a file.
Different Ways of using the “awk” Command to Print the Last Column from a File:
There are two different methods in which we can use the “awk” command to print the last column from a file. Although, these two methods can be used interchangeably because after all, they render the very same output, however, the first method is more suitable for the situation where you know the exact number of columns of a file and the second method is helpful when the total number of columns is unknown. Let us take a look at both these methods one by one.
Note: We have used Linux Mint 20 for demonstrating both of these methods, however, you are free to select any flavor of Linux of your choice.
Method # 1: When you know the Total Number of Columns of a File:
This method can be used when you know the exact number of columns in a file e.g. 3, 5, 10, etc. For demonstrating this method, the following steps should be performed in the specified order:
Create a text file with any name of your choice in your Home folder. In this scenario, we have named it as awk.txt. Now double click on this file to open it and type the data shown in the image below in your text file. There are a total of three different columns and the columns are separated from each other by tab space. You can also type any random data of your choice.
After creating this file, you have to save it and close it. Now launch the terminal in Linux Mint 20 by clicking on its icon located on the taskbar. The Linux Mint 20 terminal is also shown in the following image:

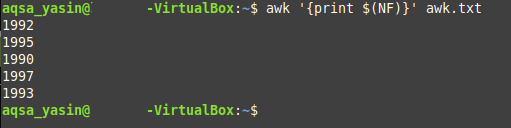
Now type the below-mentioned command in your terminal and then press the Enter key to execute it:
Here, you need to replace ColNum with the column number of the last column. For example, the text file that we have created has a total of three columns which means that the column number of the last column will be 3. Since our goal is to only print the last column of this file, so we have replaced ColNum with 3. Whenever a column number is proceeded by the “$” symbol, then this means that we want to access the values of that column. Moreover, you also have to replace “file” with the exact name of your text file. In our case, the file name was awk.txt.
![]()
As soon as you will hit the Enter key, all the values of the last column of the file awk.txt will appear on your terminal as shown in the following image. The awk command will read this column whereas the print command will be responsible for displaying its values on the terminal.
Method # 2: When the Total Number of Columns of a File is Unknown:
This method is generally used when you do not know about the total number of columns in a file. For printing the last column of a file through this method, you will have to proceed as follows:
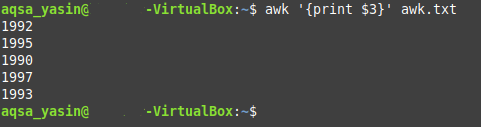
We are using the same text file that we have created for the method above. All we have to do is to launch the terminal and then type the following command in it:
Here, NF is a variable whose job is to explicitly print the last column from a file. For example, if there are 10 or 20 or even more columns in a file but you do not know their exact number and you still want to access the last column, then this variable can prove to be very helpful for you. Again, you need to replace “file” with the name of your text file. In our case, since we have used the same file as that of Method # 1, therefore, we have replaced file.txt with awk.txt.
![]()
After typing this command in your terminal, you need to run it by pressing the Enter key. You will notice that the output of this command is identical to the output of the command used in the method above i.e. the last column of the text file which contained the year data has been successfully printed on the terminal.
Conclusion:
In this article, we gave you the guidance about printing only the last column from a file while making use of the “awk” command. There are a lot more aspects of this command which can be explored in detail i.e. this command can also be used in conjunction with other different commands to render a different kind of output. However, for the scope of today’s discussion, our concern was only to demonstrate its usage for printing the last column from a file. We presented to you the two different ways of doing the same thing. Now it entirely depends on your situation that which of these methods you choose to follow.
]]>- Scan the files, line by line.
- Split each line into fields/columns.
- Specify patterns and compare the lines of the file to those patterns
- Perform various actions on the lines that match a given pattern
In this article, we will explain the basic usage of the awk command and how it can be used to split a file of strings. We have performed the examples from this article on a Debian 10 Buster system but they can be easily replicated on most Linux distros.
The sample file we will be using
The sample file of strings that we will be using in order to demonstrate the usage of the awk command is as follows:
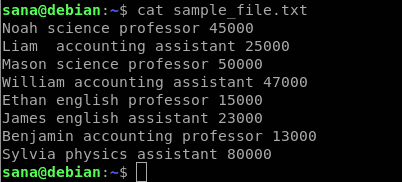
This is what each column of the sample file indicates:
- The first column contains the name of employees/teachers in a school
- The second column contains the subject that the employee teaches
- The third column indicates whether the employee is a professor or assistant professor
- The fourth column contains the pay of the employee
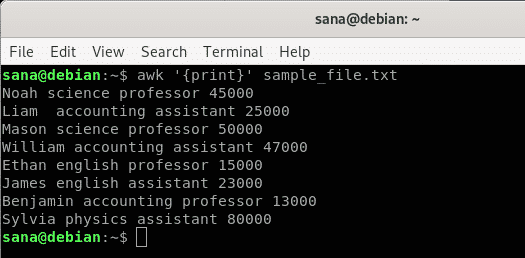
Example 1: Use Awk to print all lines of a file
Printing each and every line of a specified file is the default behavior of the awk command. In the following syntax of the awk command, we are not specifying any pattern that awk should print, thus the command is supposed to apply the “print” action to all the lines of the file.
Syntax:
Example:
In this example, I am telling the awk command to print the contents of my sample file, line by line.
Example 2: Use awk to print only the lines that match a given pattern
With awk, you can specify a pattern and the command will print only the lines matching that pattern.
Syntax:
Example:
From the sample file, if I want to print only the line(s) that contain the variable ‘B’, I can use the following command:

To make the example more meaningful, let me print only the information about employees that are ‘professor’s.

The command only prints the lines/entries that contain the string “professor” thus we have more valuable information derived from the data.
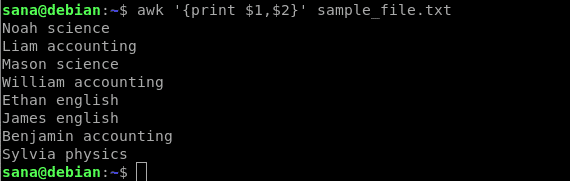
Example 3. Use awk to split the file so that only specific fields/columns are printed
Instead of printing the whole file, you can make awk to print only specific columns of the file. Awk treats all words, separated by white space, in a line as a column record by default. It stores the record in a $N variable. Where $1 represents the first word, $2 stores the second word, $3 the fourth, and so on. $0 stores the whole line so the who line is printed, as explained in example 1.
Syntax:
Example:
The following command will print only the first column(name) and the second column(subject) of my sample file:
Example 4: Use Awk to count and print the number of lines in which a pattern is matched
You can tell awk to count the number of lines in which a specified pattern is matched and then output that ‘count’.
Syntax:
filename.txt
Example:
In this example, I want to count the number of persons teaching the subject “english”. Therefore I will tell the awk command to match the pattern “english” and print the number of lines in which this pattern is matched.

The count here suggests that 2 people are teaching english from the sample file records.
Example 5: Use awk to print only lines with more than a specific number of characters
For this task, we will be using the built-in awk function called “length”. This function returns the length of the input string. Thus, if we want awk to print only lines with more than, or even less than, the number of characters, we can use the length function in the following manner:
For printing lines with characters greater than a number:
For printing lines with characters less than a number:
Where n is the number of characters you want to specify for a line.
Example:
The following command will print only the lines from my sample file who have characters more than 30:

Example 6: Use awk to save the command output to another file
By using the redirection operator ‘>’, you can use the awk command to print its output to another file. This is the way you can use it:
Example:
In this example, I will be using the redirection operator with my awk command to print only the names of the employees(column 1) to a new file:
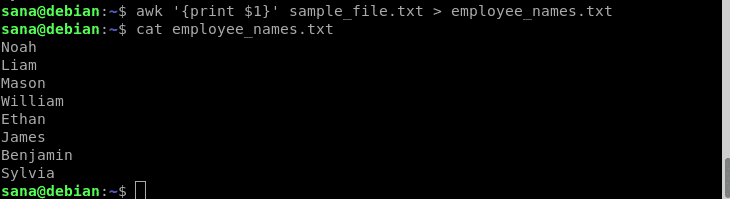
I verified through the cat commands that the new file only contains the names of the employees.
Example 7: Use awk to print only non-empty lines from a file
Awk has some built-in commands that you can use to filter the output. For example, the NF command is used to keep a count of the fields within the current input record. Here, we will use the NF command to print only the non-empty lines of the file:
Obviously, you can use the following command to print the empty lines:
Example 8: Use awk to count the total lines in a file
Another built-in function called NR keeps a count of the number of input records(usually lines) of a given file. You can use this function in awk as following to count the number of lines in a file:

This was the basic information you need to start with splitting files with the awk command. You can use the combination of these examples to fetch more meaningful information from your file of strings through awk.
]]>Syntax:
The syntax for four types of conditional statements is mentioned below.
- if statement
statement
}
The statement executes when the if condition returns true.
- if-else statement
statement-1
}
else{
statement-2
}
The statement-1 executes when the if condition is true and the statement-2 executes when if return false.
- if-elseif statement
statement-1
}
elseif{
statement-2
}
elseif{
statement-3
}
…….
else{
statement-n
}
This conditional statement is used for executing a statement based on multiple if condition. If the first condition is false then it checks the second condition. If the second condition is false then it checks the third condition and so on. If all conditions return false then it will execute the statement of else part.
- Ternary (?:) operator
Ternary operator can be used as an alternative of if-else statement. If the condition true the statement-1 will execute and if the condition false then statement-2 will execute.
Example-1: Using simple if in awk
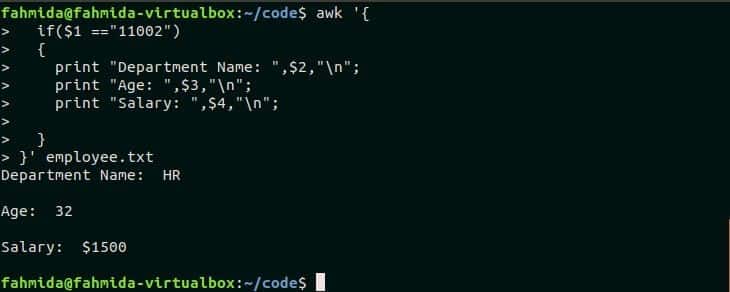
Create a text file named emplyee.txt with the following content. Suppose, you have to find out the department name, age, and salary of the employee whose id is 11002.
employee.txt
11002 HR 32 $1500
11003 Marketing 26 $1200
11004 HR 25 $2500
A simple if condition is used in the following script to search the id 11002 in the first field of the file. If the condition becomes true then it will print the values of the other fields of the corresponding line otherwise nothing will be printed.
if($1 =="11002")
{
print "Department Name: ",$2,"\n";
print "Age: ",$3,"\n";
print "Salary: ",$4,"\n";
}
}' employee.txt
Output:
The id, 1102 exists in the file. So, it printed the other values of the employee.
Example-2: Using if-else in awk
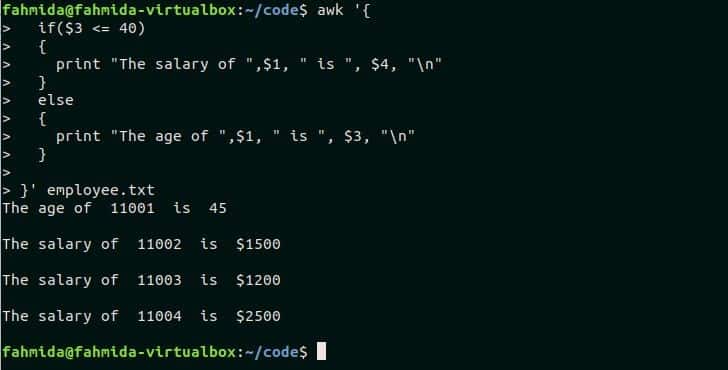
Suppose, you want to print the salary information of the employees whose age is less than or equal to 40 and print the age information for other employees. The following awk script can do this task. There is only one employee in employee.txt file whose age is more than 40 and all other employee’s age is less than 40.
if($3 <= 40)
{
print "The salary of ",$1, " is ", $4, "\n"
}
else
{
print "The age of ",$1, " is ", $3, "\n"
}
}' employee.txt
Output:
The following output will appear after running the script.
Example-3: Using if-elseif in awk script
Create a text file named person.txt with the following content.
person.txt
MARTIN Male Service Holder
LILY Female Manager
ROBINSON Male CEO
Create a awk file named if_elseif.awk with the following code to print the favorite color of each person whose name exists in the file. If-elseif statement is used in the script to do this task. The script will read the first field value of the file, employee.txt and check with a particular value. If the first if condition becomes false then it will check the second if condition and so on. When any if condition becomes true then a color value will be assigned. If all conditions become false then None will be assigned as the color value. The favorite color of each person will print or “No person found” will print if no person name matches.
if_elseif.awk
name=$1;
if ( name=="JACKSON" ) color="Blue";
else if (name=="MARTIN") color="Black";
else if (name=="LILY") color="Red";
else if (name=="ROBINSON") color="White";
else color="None";
if(color!="None") print "The favorite color of ", name, "is ", color;
else print "No person found";
}
Run the following command to execute the file if_elseif.awk with person.txt
Output:
The following output will appear after running the command.

Example-4: Using ternary operator in awk
The third field of person.txt file contains the profession of each person. The following ternary operator reads each line of the file and matches the third field value with “Manager”. If the value matches then it will print the name of the person and otherwise it will print the gender of the person.
Output:
The following output will appear after executing the script. One person with “Manager profession exists in the person.txt. So, the name of one person is printed and gender is printed for other persons.

Example-5: Using multiple conditions in if statement
Logical OR and Logical AND can be used to define multiple conditions in the conditional statement of awk script. The following awk script reads each line of employee.txt and checks the age and designation with particular values. Logical AND is used in the if condition. When the age value is greater than or equal to 30 and designation is “HR” then the corresponding employee id and salary will print.
$1, " and ", "Salary: ", $4, "\n";}' employee.txt
Output:
The following output will appear after executing the script. There is only one employee exists with the designation, “HR” in employee.txt. Id and salary information for this employee is printed here.

Conclusion:
Most common uses of the conditional statement of any standard programming are supported by awk command. How you can use single and multiple conditions in awk is explained by using very simple examples here. Hope after practicing these examples the learner will be able to use conditional statement properly in awk script.
]]>Syntax:
A name has to declare for the array variable. arrayName is the name of the array here. Every array has to use the third bracket to define the key or index and it will be any string value for the associative array. Value can be any character, number or string that will store in the particular index of the array.
Example-1: Defining and reading one-dimensional array in awk
A one-dimensional array can store a single column data list. This type of array contains a single key and value for each array element. This array can be used in awk command like other programming languages. In this example, an array named book is declared with three elements and for loop is used to read and print each element. Run the following command from the terminal.
book["JS"]="Effective JavaScript";
book["CSS"]="Learning Web Design";}
END{for (i in book) print "The book of ", i, " is ",book[i];}'
Output:

Example-2: Defining and reading two-dimensional array in awk
A two-dimensional array is used to store tabular data list that contains a fixed number of rows and columns. The two-dimensional array named students is declared in this example that contains three elements. Here, student id and name are used as key values of the array. Like the previous example, for-in loop is used in the awk script to print the values of the array. Run the following script from the terminal.
students["87462,Mohammed Ali"] = 87;
students["98376,Sakib Al Hasan"] = 99;
students["79937,Musfikur Rahman"] = 88;
print "(ID,Name) => Marks";
}
END { for (i in students) print "(", i, ") => ", students[i]; }'
Output:
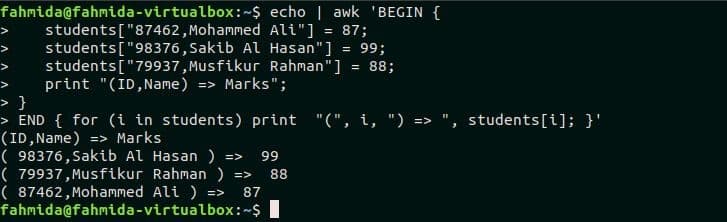
Example-3: Deleting array element
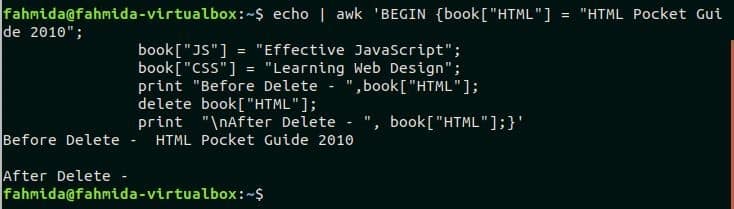
Any value of the array can be deleted based the key value. Here, book array with three elements is defined in the beginning of the script. Next, the value of the key HTML is deleted by using delete command. The element value of HTML key is printed before and after the delete command. Run the following command to check the output.
book["JS"] = "Effective JavaScript";
book["CSS"] = "Learning Web Design";
print "Before Delete - ",book["HTML"];
delete book["HTML"];
print "\nAfter Delete - ", book["HTML"];}'
Output:
The output shows that the value of HTML index is empty after executing delete command.
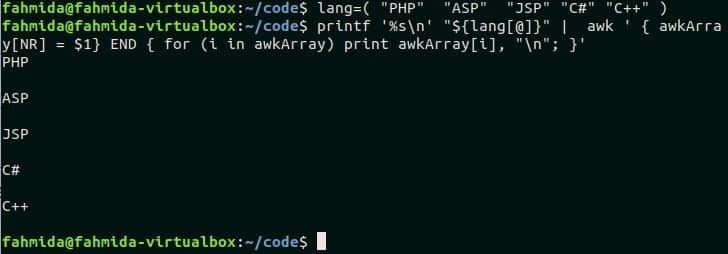
Example-4: Reading bash array in awk
In the previous examples, the array is declared in the awk command and iterated by for-in loop. But you can read any bash array by awk script. In this example, a bash array named lang is declared in the first command. In the second command, the bash array values are passed into the awk command that stores all the elements into an awk array named awkArray. The values of awkArray array are printed by using for loop. Run the following command from the terminal to check the output.
$ printf '%s\n' "${lang[@]}" | awk ' { awkArray[NR] = $1} END { for
(i in awkArray) print awkArray[i], "\n"; }'
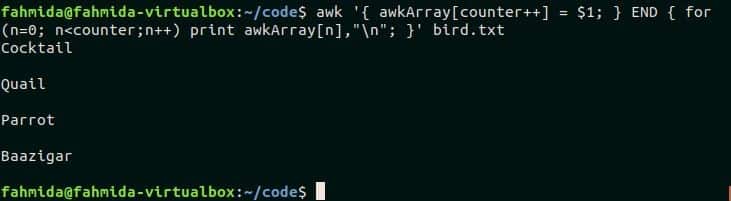
Example-5: Reading the file content into an awk array
The content of any file can be read by using awk array. Create a text file named bird.txt with the content given below.
bird.txt
Quail
Gray Parrot
Baazigar
The following awk script is used to read the content of bird.txt file and store the values in the array, awkArray. for loop is used to parse the array and print the values in the terminal. Run the following script from the terminal.
print awkArray[n],"\n"; }' bird.txt
Output:
The script prints the content of bird.txt.
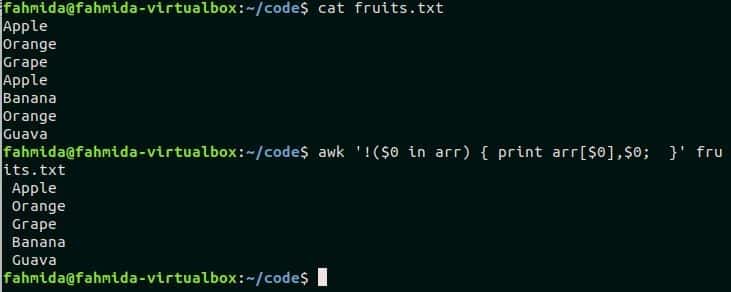
Example-6: Removing duplicate entries from a file
awk script can be used to remove duplicate data from any text file. Create a text file named fruits.txt with the following content. There are two duplicate data in the file. These are Apple and Orange.
fruits.txt
Orange
Grape
Apple
Banana
Orange
Guava
The following awk script will read every line from the text file, fruits.txt and check the current line exists or not in the array, arr. If the line exists in the array then it will not store the line in the array and will not print the value in the terminal. So, the script will store only the unique lines from the file into the array and print. Run the commands from the terminal.
$ awk '!($0 in arr) { print arr[$0],$0; }' fruits.txt
Output:
The first will print the content of the file, fruits.txt and the second command will print the content of fruits.txt after omitting duplicate lines from the file.
Conclusion:
This tutorial shows the various uses of the array in awk script by using different examples with explanation. Bash array and any text file content can also be accessed by using awk array. If you are new in awk programming then this tutorial will help you to learn the uses of awk array from the basic and you will be able to use array in awk script properly.
]]>Syntax:
- for loop declaration:
statements
}
First part is used to initialize the variable for starting for loop. The second part contains the termination condition to control the iteration of the loop and the loop will continue until the condition is true. The last part will increment or decrement the initialization variable based on the first part.
- for-in declaration
statements
}
for-in loop is used to do those tasks where the number of iteration of the loop is not fixed. for-in loop is mainly used to parse an array or list of data. The loop reads each data from the array or list and stores the value to a variable in each iteration.
Example-1: Using simple for loop
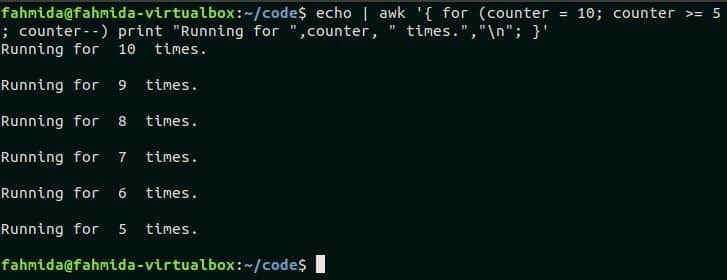
A simple for loop is used in the following script. Here, counter variable is initialized by 10 and the loop will terminate when the value of counter is less than 5. The script will print the counter values from 10 to 5. Run the command from the terminal.
print "Running for ",counter, " times.","\n"; }'
Output:
The following output will appear after executing the command.
Example-2: Using for-in loop to read an array
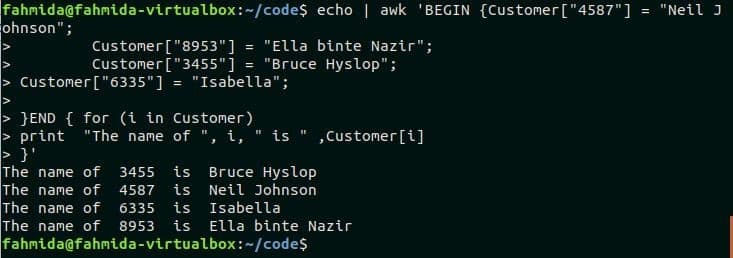
An array named Customer is declared in the following script where the customer’s id is set as an array index and the customer’s name is set as array value. for-in loop is used here to iterate each index from the array and print the customer’s name. Run the script from the terminal.
Customer["8953"] = "Ella binte Nazir";
Customer["3455"] = "Bruce Hyslop";
Customer["6335"] = "Isabella";
}END { for (i in Customer)
print "The name of ", i, " is " ,Customer[i]
}'
Output:
The following output will appear after executing the script.
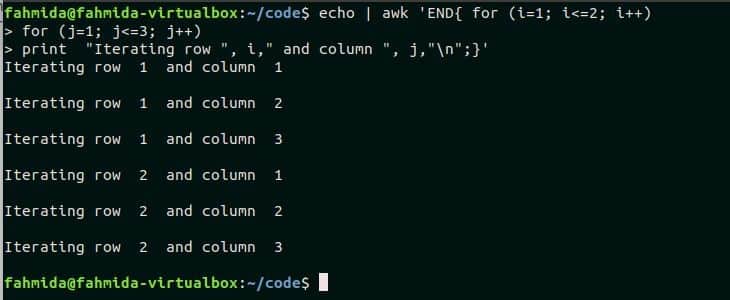
Example-3: Using nested for loop
When a for loop is declared under another for loop then it is called nested for loop. The outer loop that is used in this script will iterate for 2 times and the inner loop will iterate for 3 times. So, the print statement will execute for, (2X3=6) 6 times. Run the script from the terminal.
for (j=1; j<=3; j++)
print "Iterating row ", i," and column ", j,"\n";}'
Output:
The following output will appear after running the script.
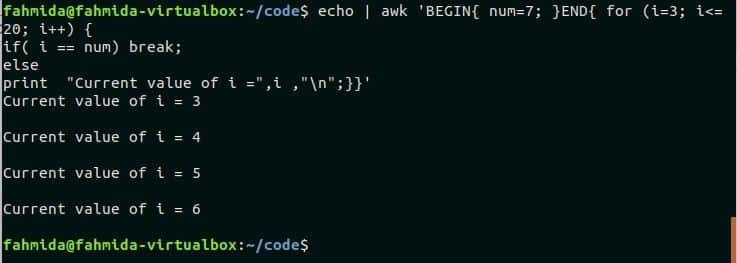
Example-4: Using for loop with break statement
break statement is used in any loop to terminate the loop before reaching the termination condition based on the particular condition. In the following script, for loop will start from 3 and it will terminate when the value of i is greater than 20. But when the value of i will be equal to the variable num then the if condition will true and the loop will terminate for the break statement.
if( i == num) break;
else
print "Current value of i =",i ,"\n";}}'
Output:
Here, if condition is false for four iterations when the value of i is 3,4,5 and 6. So, the following output is printed for the four iterations.
Example-5: Using for loop with continue statement
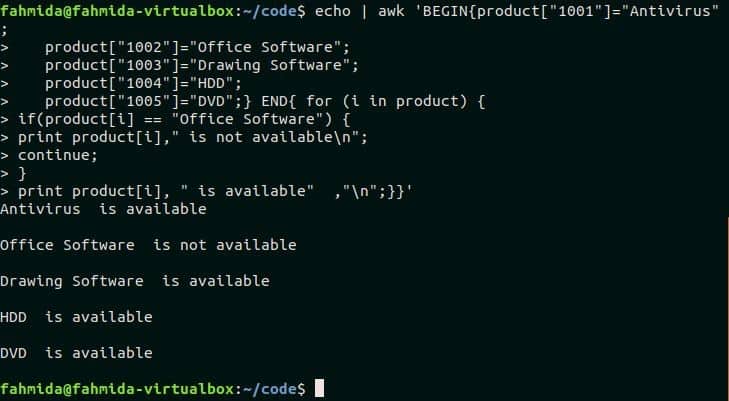
Continue statement is used in any loop to omit any statement based on any particular condition. An array named product is declared in the following script. for-in loop is used to iterate the array and check each value with “Office Software“. If the value matches then an unavailable message will print by omitting available message for continue statement, otherwise unavailable message will print. Run the script from the terminal.
product["1002"]="Office Software";
product["1003"]="Drawing Software";
product["1004"]="HDD";
product["1005"]="DVD";} END{ for (i in product) {
if(product[i] == "Office Software") {
print product[i]," is not available\n";
continue;
}
print product[i], " is available" ,"\n";}}'
Output:
The following output will appear after running the script.
Example-6: Using for loop in awk file
Create a text file named sales.txt and add the following content to practice this example.
sales.txt
2016 80000
2017 83000
2018 86000
2019 90000
Create an awk file named cal_sal.awk with the following script to calculate the total sales amount of the file sales.txt. The second field contains the yearly sales amount in the file sales.txt. In the script, the sales array will store all values of the second field and sum variable is initialized with 0 to add all values of sales array. Next, for-in loop is used to iterate each element of the sales array and add the value with the sum variable. Lastly, print statement is used to print the value of sum variable to display the total sales amount.
cal_sal.awk
sales[i++]=$2;
sum=0;
}
END{
for (i in sales)
{
sum=sum+sales[i];
}
print "Total sales amount=" sum;
}
Run the following command to execute the script of cal_sal.awk file.
Output:
There are 5 records in the sales.txt file and the sum of the sales amount is 409000 that is printed after executing the script.

Conclusion:
Different uses of for loop in awk command is tried to explain in this tutorial. Hope, the reader will get a clear idea on using for loop in awk script and able to use for loop properly in awk programming.
]]>Example -1: Defining and printing variable
`awk` command uses ‘-v’ option to define the variable. In this example, the myvar variable is defined in the `awk` command to store the value, “AWK variable” that is printed later. Run the following command from the terminal to check the output.
Output:

Example – 2: Using shell variable in awk with a single quote and double quote
The example shows how the shell variable can be used `awk` command. Here, a shell variable, myvar is declared with the value, “Linux Hint” in the first command. ‘$’ symbol is used with a shell variable name to read the value. The second command reads the variable, $myval with a single quote(‘) and the third command reads the variable $myvar with double quote(“) in the `awk` statement.
$ echo | awk -v awkvar='$myvar' '{ print awkvar; }'
$ echo | awk -v awkvar="$myvar" '{ print awkvar; }'
Output:
It is shown in the output that the value of $myvar can’t be read when it is enclosed with a single quote (‘) and the output is $myvar. The value of $myvar is printed when it is enclosed with a double quote (“).

Example – 3: Reading ARGC variable in awk
ARGC variable is used to count the total number of command line arguments. Three command line arguments variables (t1, t2, t3) are passed in the following awk script. Here, the total number of arguments with the script is 4. Run the script from the terminal.
Output:
The following output will appear after running the script.

Example – 4: Reading file content by argument variables
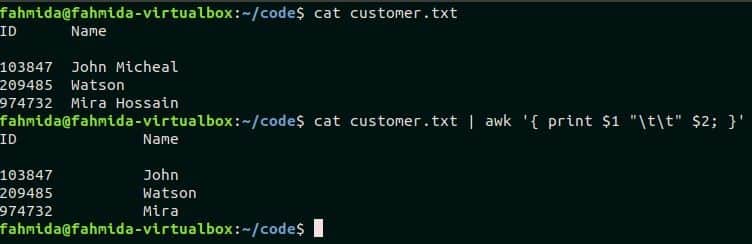
Create a text file named customer.txt with the following content to practice this example. Here, every field of the file is separated by single tab space.
customer.txt
103847 John Micheal
209485 Watson
974732 Mira Hossain
Awk command can read each field from any text file by argument variables. There are two fields in customer.txt file. These are ID and Name. The following script will print these two fields by argument variables, $1 and $2 by separating two tab spaces. Run the script from the terminal.
$ cat customer.txt | awk '{ print $1 "\t\t" $2;}'
Output:
The following output will appear after running the above commands.
Example- 5: Using built-in variable, FS and field separator option with awk command
FS variable is used in awk command as a field separator. Space is used as a default value of FS. The following command will read the file customer.txt using space as field separator and print the file content. Run the command from the terminal.
Output:
The following output will appear after running the script.

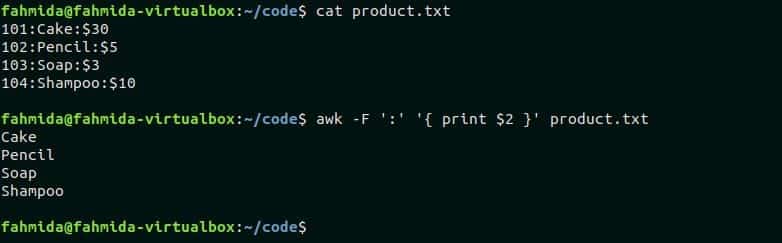
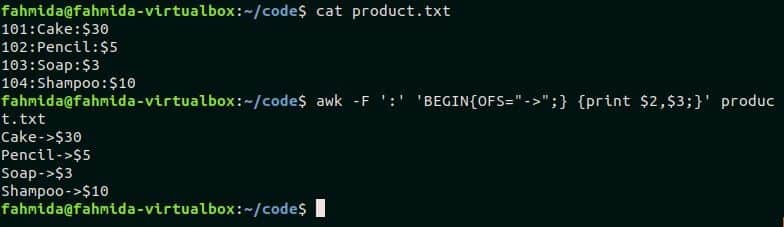
Awk command can use other characters as field separator by using the ‘-F’ option. Create a text file named product.txt with the following content where ‘:’ is used as a field separator.
product.txt
102:Pencil:$5
103:Soap:$3
104:Shampoo:$10
There are three fields in the file, product.txt that contains product id, name and price. The following awk command will print only the second field of each line. Run the commands from the terminal.
$ awk -F ':' '{ print $2 }' product.txt
Output:
Here, the first command printed the content of product.txt and the second command printed only the second field of the file.
Example – 6: Using built-in variable, NR with awk command
NR variable is used in awk command to count the total number of records or lines of a file. Create a text file named student.txt to test the function of this variable.
student.txt
John 20 3
Mira 22 1
Ella 18
Charle 15 8
The following awk script will print the first three lines of product.txt file. Here, a condition is added by using the NR variable. The command will print those lines where the NR value is less than 4. Run the script from the terminal.
Output:
The following output will appear after running the script.

Example – 7: Using built-in variable, NF with awk command
NF variable is used in awk command to count the total number of fields in each line of a file. The following awk script is applied for the file, student.txt which is created in the previous example. The script will print those lines from student.txt file where the total fields are less than 3. Run the command from the terminal.
Output:
There is just one line exists in the file where the total number of fields is less than 3 that is printed as output.

Example – 8: Using built-in variable, OFS with awk command
OFS variable is used in awk command to add output field separator in the output. product.txt file is used in this example to show the use of OFS variable. ‘:’ is used as field separator in product.txt file. The following awk script used ‘->’ as OFS value and, the second and the third fields of the file will print by adding this separator. Run the commands from the terminal.
$ awk -F ':' 'BEGIN{OFS="->";} {print $2,$3;}' product.txt
Output:
The following output will print after running the commands.
Conclusion:
Most common uses of awk variables are tried to explain in this tutorial. Hope, the reader will be able to use awk variables properly in the script after practicing this tutorial.
]]>20 awk examples
Many utility tools exist in the Linux operating system to search and generate a report from text data or file. The user can easily perform many types of searching, replacing and report generating tasks by using awk, grep and sed commands. awk is not just a command. It is a scripting language that can be used from both terminal and awk file. It supports the variable, conditional statement, array, loops etc. like other scripting languages. It can read any file content line by line and separate the fields or columns based on a specific delimiter. It also supports regular expression for searching particular string in the text content or file and takes actions if any match founds. How you can use awk command and script is shown in this tutorial by using 20 useful examples.
Contents:
- awk with printf
- awk to split on white space
- awk to change the delimiter
- awk with tab-delimited data
- awk with csv data
- awk regex
- awk case insensitive regex
- awk with nf (number of fields) variable
- awk gensub() function
- awk with rand() function
- awk user defined function
- awk if
- awk variables
- awk arrays
- awk loop
- awk to print the first column
- awk to print the last column
- awk with grep
- awk with the bash script file
- awk with sed
Using awk with printf
printf() function is used to format any output in most of the programming languages. This function can be used with awk command to generate different types of formatted outputs. awk command mainly used for any text file. Create a text file named employee.txt with the content given below where fields are separated by tab (‘\t’).
employee.txt
1002 Jafar Iqbal 60000
1003 Meher Nigar 30000
1004 Jonny Liver 70000
The following awk command will read data from employee.txt file line by line and print the first filed after formatting. Here, “%10s\n” means that the output will be 10 characters long. If the value of the output is less than 10 characters then the spaces will be added at the front of the value.
Output:

awk to split on white space
The default word or field separator for splitting any text is white space. awk command can take text value as input in various ways. The input text is passed from echo command in the following example. The text, ‘I like programming’ will be split by default separator, space, and the third word will be printed as output.
Output:

awk to change the delimiter
awk command can be used to change the delimiter for any file content. Suppose, you have a text file named phone.txt with the following content where ‘:’ is used as field separator of the file content.
phone.txt
+880:1855:456:907
+9:7777:38644:808
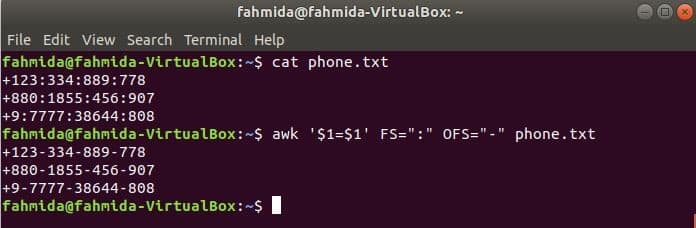
Run the following awk command to change the delimiter, ‘:’ by ‘-’ to the content of the file, phone.txt.
$ awk '$1=$1' FS=":" OFS="-" phone.txt
Output:
awk with tab-delimited data
awk command has many built-in variables which are used to read the text in different ways. Two of them are FS and OFS. FS is input field separator and OFS is output field separator variables. The uses of these variables are shown in this section. Create a tab separated file named input.txt with the following content to test the uses of FS and OFS variables.
Input.txt
Server-side scripting language
Database Server
Web Server
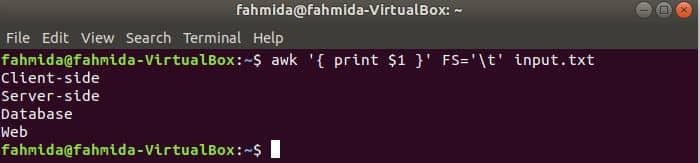
Using FS variable with tab
The following command will split each line of input.txt file based on the tab (‘\t’) and print the first field of each line.
Output:
Using OFS variable with tab
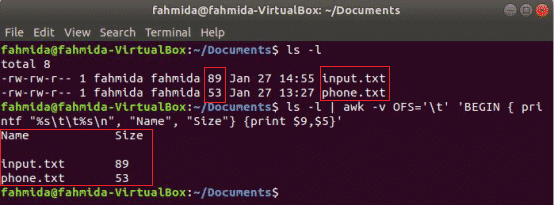
The following awk command will print the 9th and 5th fields of ‘ls -l’ command output with tab separator after printing the column title “Name” and “Size”. Here, OFS variable is used to format the output by a tab.
$ ls -l | awk -v OFS='\t' 'BEGIN { printf "%s\t%s\n", "Name", "Size"} {print $9,$5}'
Output:
awk with CSV data
The content of any CSV file can be parsed in multiple ways by using awk command. Create a CSV file named ‘customer.csv’ with the following content to apply awk command.
customer.txt
1, Sophia, [email protected], (862) 478-7263
2, Amelia, [email protected], (530) 764-8000
3, Emma, [email protected], (542) 986-2390
Reading single field of CSV file
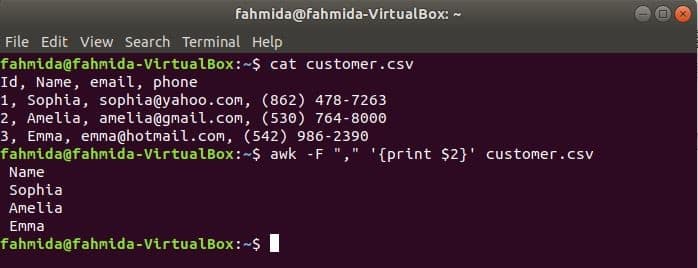
‘-F’ option is used with awk command to set the delimiter for splitting each line of the file. The following awk command will print the name field of the customer.csv file.
$ awk -F "," '{print $2}' customer.csv
Output:
Reading multiple fields by combining with other text
The following command will print three fields of customer.csv by combining title text, Name, Email, and Phone. The first line of the customer.csv file contains the title of each field. NR variable contains the line number of the file when awk command parses the file. In this example, the NR variable is used to omit the first line of the file. The output will show the 2nd, 3rd and 4th fields of all lines except the first line.
Output:

Reading CSV file using an awk script
awk script can be executed by running awk file. How you can create awk file and run the file is shown in this example. Create a file named awkcsv.awk with the following code. BEGIN keyword is used in the script for informing awk command to execute the script of the BEGIN part first before executing other tasks. Here, field separator (FS) is used to define splitting delimiter and 2nd and 1st fields will be printed according to the format used in printf() function.
Run awkcsv.awk file with the content of the customer.csv file by the following command.
Output:

awk regex
The regular expression is a pattern that is used to search any string in a text. Different types of complicated search and replace tasks can be done very easily by using the regular expression. Some simple uses of the regular expression with awk command are shown in this section.
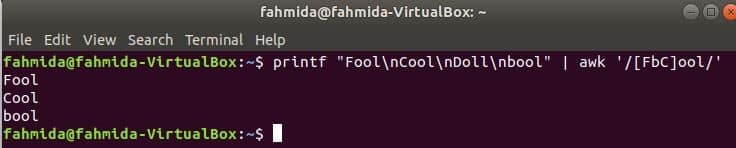
The following command will match the word Fool or bool or Cool with the input string and print if the word founds. Here, Doll will not match and not print.
Output:
Searching string at the start of the line
‘^’ symbol is used in the regular expression to search any pattern at the starting of the line. ‘Linux’ word will be searched at the starting of each line of the text in the following example. Here, two lines start with the text, ‘Linux’ and those two lines will be shown in the output.
a popular blog site" | awk '/^Linux/'
Output:
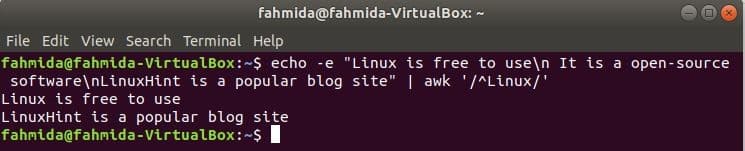
Searching string at the end of the line
‘$’ symbol is used in the regular expression to search any pattern at the end of each line of the text. ‘Script’ word is searched in the following example. Here, two lines contain the word, Script at the end of the line.
Output:
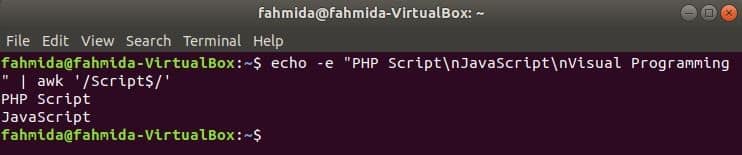
Searching by omitting particular character set
‘^’ symbol indicates the starting of the text when it is used in front of any string pattern (‘/^…/’) or before any character set declared by ^[…]. If the ‘^’ symbol is used inside the third bracket, [^…] then the defined character set inside the bracket will be omitted at the time of searching. The following command will search any word that is not starting with ‘F’ but ending with ‘ool’. Cool and bool will be printed according to the pattern and text data.
Output:

awk case insensitive regex
By default, regular expression does case sensitive search when searching any pattern in the string. Case insensitive search can be done by awk command with the regular expression. In the following example, tolower() function is used to do case insensitive search. Here, the first word of each line of the input text will be converted to lower case by using tolower() function and match with the regular expression pattern. toupper() function can also be used for this purpose, in this case, the pattern must be defined by all capital letter. The text defined in the following example contains the searching word, ‘web’ in two lines which will be printed as output.
Output:
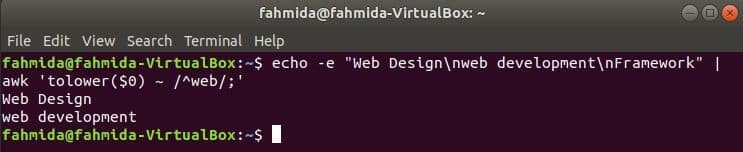
awk with NF (number of fields) variable
NF is a built-in variable of awk command which is used to count the total number of fields in each line of the input text. Create any text file with multiple lines and multiple words. the input.txt file is used here which is created in the previous example.
Using NF from the command line
Here, the first command is used to display the content of input.txt file and second command is used to show the total number of fields in each line of the file using NF variable.
$ awk '{print NF}' input.txt
Output:
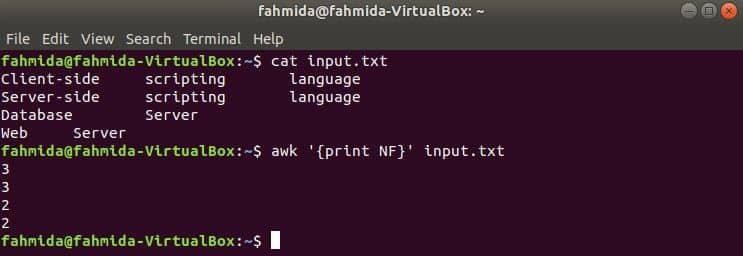
Using NF in awk file
Create an awk file named count.awk with the script given below. When this script will execute with any text data then each line content with total fields will be printed as output.
count.awk
{print "[Total fields:" NF "]"}
Run the script by the following command.
Output:
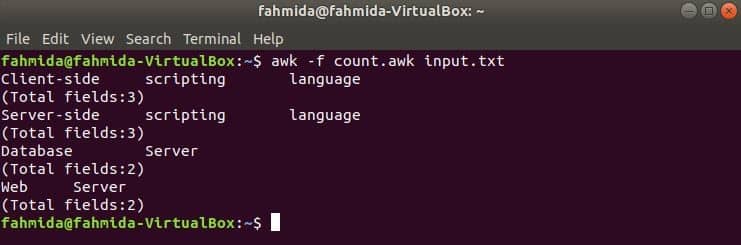
awk gensub() function
getsub() is a substitution function that is used to search string based on particular delimiter or regular expression pattern. This function is defined in ‘gawk’ package which is not installed by default. The syntax for this function is given below. The first parameter contains the regular expression pattern or searching delimiter, the Second parameter contains the replacement text, the third parameter indicates how the search will be done and the last parameter contains the text in which this function will be applied.
Syntax:
Run the following command to install gawk package for using getsub() function with awk command.
Create a text file named ‘salesinfo.txt’ with the following content to practice this example. Here, the fields are separated by a tab.
salesinfo.txt
Tue 800000
Wed 750000
Thu 200000
Fri 430000
Sat 820000
Run the following command to read the numeric fields of the salesinfo.txt file and print the total of all sales amount. Here, the third parameter, ‘G’ indicates the global search. That means the pattern will be searched in the full content of the file.
Output:

awk with rand() function
rand() function is used to generate any random number greater than 0 and less than 1. So, it will always generate a fractional number less than 1. The following command will generate a fractional random number and multiply the value with 10 to get a number more than 1. A fractional number with two digits after the decimal point will be printed for applying printf() function. If you run the following command multiple times then you will get different output every time.
Output:
awk user defined function
All functions which are used in the previous examples are built-in functions. But you can declare a user-defined function in your awk script to do any particular task. Suppose, you want to create a custom function to calculate the area of a rectangle. To do this task, create a file named ‘area.awk’ with the following script. In this example, a user-defined function named area() is declared in the script that calculates the area based on the input parameters and returns the area value. getline command is used here to take input from the user.
area.awk
function area(height,width){
return height*width
}
# Starts execution
BEGIN {
print "Enter the value of height:"
getline h < "-"
print "Enter the value of width:"
getline w < "-"
print "Area = " area(h,w)
}
Run the script.
Output:
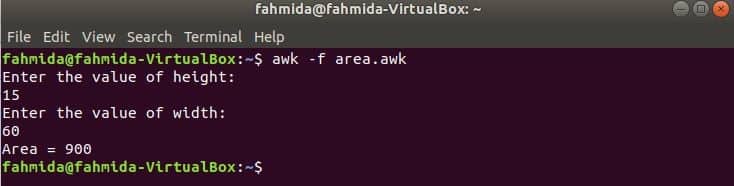
awk if example
awk supports conditional statements like other standard programming languages. Three types of if statements are shown in this section by using three examples. Create a text file named items.txt with the following content.
items.txt
Mouse A4Tech
Printer HP $200
Simple if example:
he following command will read the content of the items.txt file and check the 3rd field value in each line. If the value is empty then it will print an error message with the line number.
Output:
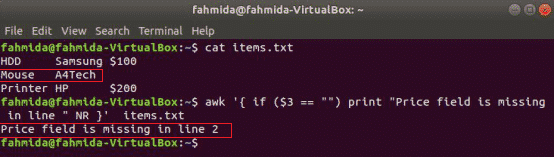
if-else example:
The following command will print the item price if the 3rd field exists in the line, otherwise, it will print an error message.
else print "item price is " $3 }' items.txt
Output:
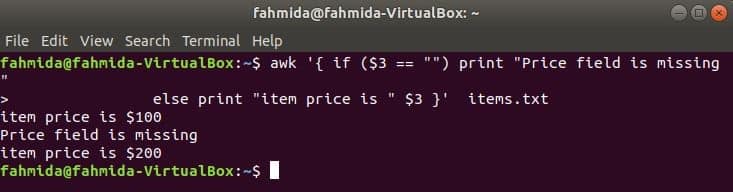
if-else-if example:
When the following command will execute from the terminal then it will take input from the user. The input value will be compared with each if condition until the condition is true. If any condition becomes true then it will print the corresponding grade. If the input value does not match with any condition then it will print fail.
getline mark < "-"
if (mark >= 90) print "A+"
else if( mark >= 80) print "A"
else if( mark >= 70) print "B+"
else print "Fail" }'
Output:
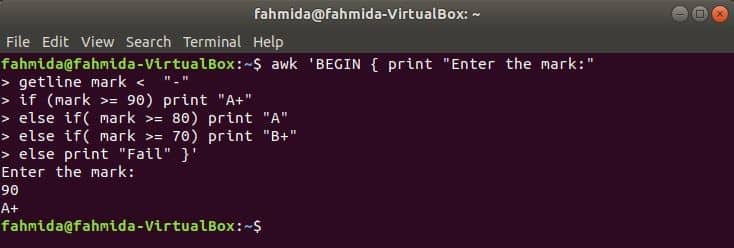
awk variables
The declaration of awk variable is similar to the declaration of the shell variable. There is a difference in reading the value of the variable. ‘$’ symbol is used with the variable name for the shell variable to read the value. But there is no need to use ‘$’ with awk variable to read the value.
Using simple variable:
The following command will declare a variable named ‘site’ and a string value is assigned to that variable. The value of the variable is printed in the next statement.
Output:

Using a variable to retrieve data from a file
The following command will search the word ‘Printer’ in the file items.txt. If any line of the file starts with ‘Printer’ then it will store the value of 1st, 2nd and 3rd fields into three variables. name and price variables will be printed.
print "item price=" price }' items.txt
Output:
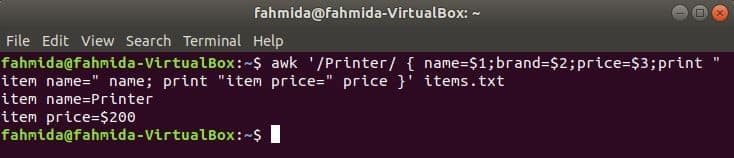
awk arrays
Both numeric and associated arrays can be used in awk. Array variable declaration in awk is same to other programming languages. Some uses of arrays are shown in this section.
Associative Array:
The index of the array will be any string for the associative array. In this example, an associative array of three elements are declared and printed.
books["Web Design"] = "Learning HTML 5";
books["Web Programming"] = "PHP and MySQL"
books["PHP Framework"]="Learning Laravel 5"
printf "%s\n%s\n%s\n", books["Web Design"],books["Web Programming"],
books["PHP Framework"] }'
Output:
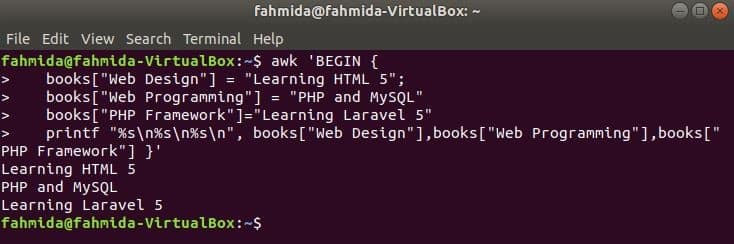
Numeric Array:
A numeric array of three elements are declared and printed by separating tab.
number[0] = 80;
number[1] = 55;
number[2] = 76;
 
# print array elements
printf "Array values: %d\t%d\t%d\n", number[0],number[1],number[2]; }'
Output:
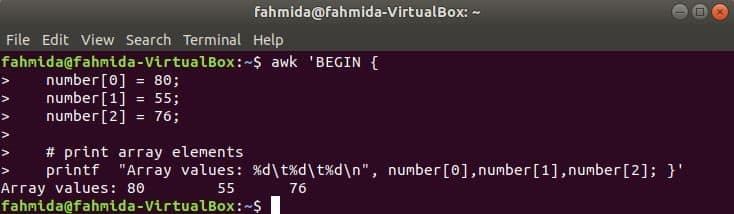
awk loop
Three types of loops are supported by awk. The uses of these loops are shown here by using three examples.
While loop:
while loop that is used in the following command will iterate for 5 times and exit from the loop for break statement.
Output:
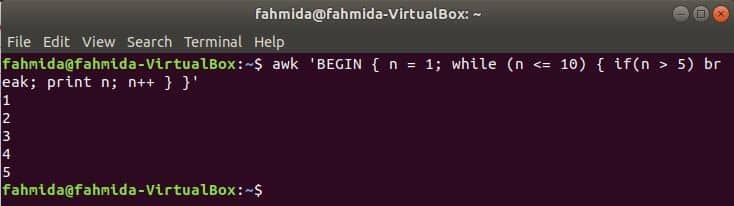
For loop:
For loop that is used in the following awk command will calculate the sum from 1 to 10 and print the value.
Output:

Do-while loop:
a do-while loop of the following command will print all even numbers from 10 to 5.
while (counter > 5) }'
Output:

awk to print the first column
The first column of any file can be printed by using $1 variable in awk. But if the value of the first column contains multiple words then only the first word of the first column prints. By using a specific delimiter, the first column can be printed properly. Create a text file named students.txt with the following content. Here, the first column contains the text of two words.
Students.txt
Abir Hossain 35<sup>th</sup> batch
John Abraham 40<sup>th</sup> batch
Run awk command without any delimiter. The first part of the first column will be printed.
Run awk command with the following delimiter. The full part of the first column will be printed.
Output:
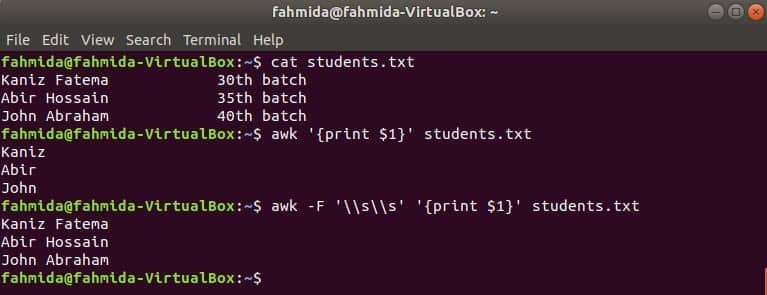
awk to print the last column
$(NF) variable can be used to print the last column of any file. The following awk commands will print the last part and full part of the last column of the students.txt file.
$ awk -F '\\s\\s' '{print $(NF)}' students.txt
Output:
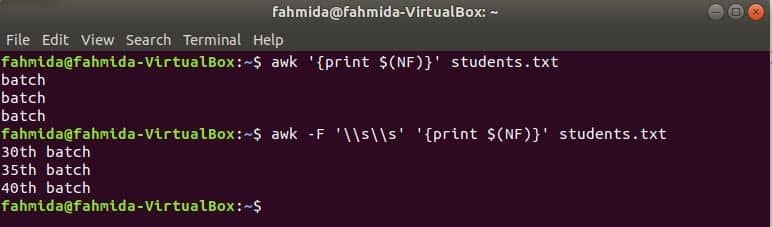
awk with grep
grep is another useful command of Linux to search content in a file based on any regular expression. How both awk and grep commands can be used together is shown in the following example. grep command is used to search information of the employee id, ‘1002’ from the employee.txt file. The output of the grep command will be sent to awk as input data. 5% bonus will be counted and printed based on the salary of the employee id, ‘1002’ by awk command.
$ grep '1002' employee.txt | awk -F '\t' '{ print $2 " will get $" ($3*5)/100 " bonus"}'
Output:
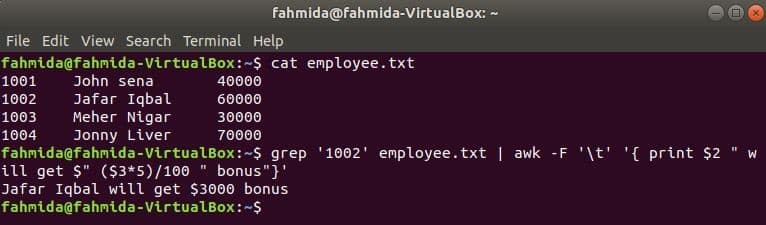
awk with BASH file
Like other Linux command, awk command can also be used in a BASH script. Create a text file named customers.txt with the following content. Each line of this file contains information on four fields. These are customer’s ID, Name, address and mobile number those are separated by ‘/’.
customers.txt
CA5455 / Virginia S Mota / 930 Bassel Street,VALLECITO,California / 415-679-5908
IL4855 / Ann A Neale / 1932 Patterson Fork Road,Chicago,Illinois / 773-550-5107
Create a bash file named item_search.bash with the following script. According to this script, the state value will be taken from the user and searched in the customers.txt file by grep command and passed to the awk command as input. Awk command will read 2nd and 4th fields of each line. If the input value matches with any state value of customers.txt file then it will print the customer’s name and mobile number, otherwise, it will print the message “No customer found”.
item_search.bash
echo "Enter the state name:"
read state
customers=`grep "$state" customers.txt | awk -F "/" '{print "Customer Name:" $2, ",
Mobile No:" $4}'`
if [ "$customers" != "" ]; then
echo $customers
else
echo "No customer found"
fi
Run the following commands to show the outputs.
$ bash item_search.bash
Output:

awk with sed
Another useful searching tool of Linux is sed. This command can be used for both searching and replacing text of any file. The following example shows the use of awk command with sed command. Here, sed command will search all employee names starts with ‘J’ and passes to awk command as input. awk will print employee name and ID after formatting.
$ sed -n '/J/p' employee.txt | awk -F '\t' '{ printf "%s(%s)\n", $2, $1 }'
Output:
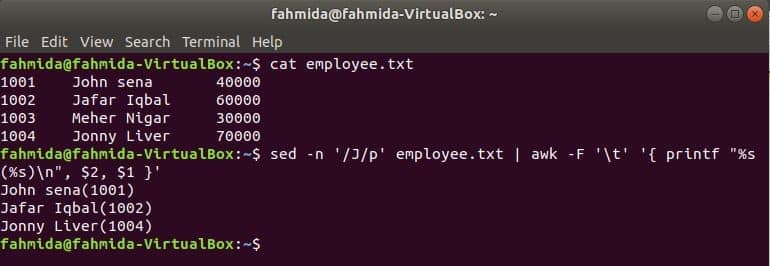
Conclusion:
You can use awk command to create different types of reports based on any tabular or delimited data after filtering the data properly. Hope, you will be able to learn how awk command works after practicing the examples shown in this tutorial.
]]>Introduction to awk
AWK is a popular language in UNIX and Linux. It got its name from its authors: Alfred Aho, Peter Weinberger, and Brian Kernighan. The awk command allows access to the AWK programming language, which is designed to process data within text streams.
Popularly used for scanning patterns and simplifying complex operations, awk helps you write effective statements for defining text patterns in a file. The awk command then processes these statements by reading one line at a time and takes an action based on the condition given.
Simply put, awk finds and replaces text, and helps sort, validate, or index the given data.
Features of AWK
awk comes with a lot of unique features:
- No compilation is necessary in awk
- Often used for data extraction
- Commonly used for performing text manipulation
- Helps generate results as needed.
Now let’s explore the power of the awk commands.
15 Interesting awk Commands
Here’s a compiled list of some interesting awk commands:
- Printing random numbers in a set – Suppose you want to print a few random numbers from a selected pool. You can specify the quantity of random numbers from this pool and ask awk to print this. Here’s an example: let’s print 10 numbers from 0 to 1000. So the awk command for this will be as follows:
awk 'BEGIN { for (i = 1; i <= 10; i++)
print int(1001 * rand()) }'
- Searching for foo or bar – What if you want to write a line in which you want to perform a simple search for foo or bar? Here’s a command that will allow you to do just that:
if (/foo/ || /bar/)
print "Found!"
- Rearranging a field – If you want to print a particular field in a particular order, awk can do it for you. Suppose you want to print the first 5 fields of a particular set in one field per line, you can use the following command:
awk ’{ i = 1
while (i <= 3) {
print $i
i++
}
}’ inputfile
- Splitting a line – In any given set of files, awk can help split a line into fields, where x is the name of the field:
$ awk '{print $x,$x}'xyz.txt
- Running several commands at once – To run several commands at once, you can use a semicolon to specify both the commands:
$ echo "Good morning! Jack" | awk '{$2="Jill"; print $0}'
- Executing an awk script – If you want to execute an awk script from a particular file, you can create a file sum_column and paste the below script in that file:
#!/usr/bin/awk -f
BEGIN {sum=0}
{sum=sum+$x}
END {print sum}In the above script, x equals the column you need to input in the file. On the successful completion of this task, you can use the following command to display the sum of the x column in the input file:
awk -f sum_column input_file.
- Using –f – When coding, it may often seem impractical to refer to the terminal. awk uses –f to perform search from a file:
awk -f script.awk inputfile
- Performing Math functions – You can also use awk for simple Math functions:
awk ’{ sum = $2 + $3 + $4 ; avg = sum / 3
> print $1, avg }’ grades
- Hello World in awk – You can print a simple Hello World in awk using the following command:
awk "BEGIN { print "Hello World!!" }"
You can also create a Hello World program. The following code will not only print the ubiquitous hello message but will also generate header information:
$ awk 'BEGIN { print "Hello World!" }'
- Printing the total number of bytes – You can find out the total bytes used by files using the following command:
ls -l . | awk '{ x += $5 } ; END \
{ print "total bytes: " x }'
total bytes: 7449362
- Anonymizing an Apache log – You can use the following code to anonymize an Apache log:
cat apache-anon-noadmin.log | \
awk 'function ri(n) \
{ return int(n*rand()); } \
BEGIN { srand(); } { if (! \
($5 in jack)) { \
jack[$5] = sprintf("%d.%d.%d.%d", \
ri(255), ri(255)\
, ri(255), ri(255)); } \
$5 = jack[$5]; print __g5_token5b610ba53dbe4 }'
- Operating in rows – If you have an address that you would like to sort in rows, you can do so using the following command:
BEGIN { RS = "" ; FS = "\n" }
{
print "Name is:", $1
print "Address is:", $2
print "City and State are:", $3
print ""
}
- Using the while loop – The while loop keeps on executing the action given to it in a repeated process until the condition is true. For example, for printing numbers from 1 to 100, you can use the following code:
awk 'BEGIN {i = 1; while (i < 100) { print i; ++i } }'
- Using the do-while loop – In this loop, the condition gets executed at the end of the loop even if the statement is false. For example, to print numbers from 1 to 100 using a do-while loop, you can use the following code:
awk 'BEGIN {i = 1; do { print i; ++i } while (i < 100) }'
- Using BEGIN and END – The BEGIN keyword is used to create a header for processing your record:
$ awk 'BEGIN {print "XXX"}
In the same way, the END keyword is used after processing the data:
END {print "File footer"}'
This concludes the list of 15 interesting awk commands. You can try these out and see the results. Hope you find it useful. If you found this article interesting, you can explore Mastering Linux Shell Scripting – Second Edition. In this book, you’ll discover everything you need to know to master shell scripting and make informed choices about the elements you employ. ]]>